PaddleOCR-VL-1.5简介
1. PaddleOCR-VL-1.5 简介¶
PaddleOCR-VL-1.5 在1.0版本上进行了进一步能力的扩展和升级优化,在文档解析 OmniDocBench v1.5 上取得了 94.5% 的更高的新 SOTA(最佳)结果。为了严格评估其对现实世界物理畸变的鲁棒性——包括扫描伪影、倾斜、弯曲、屏摄和光照变化——我们提出了 Real5-OmniDocBench 基准测试。实验结果表明,该增强模型在这一新构建的基准测试中各个场景都达到了 SOTA 性能。此外,我们通过加入印章识别和文字检测识别任务扩展了模型能力,同时保持了 0.9B 的超紧凑 VLM 规模和高效率。
关键指标:¶
核心特性:¶
-
文档解析的SOTA性能: 凭借 0.9B 的参数量,PaddleOCR-VL-1.5 在 OmniDocBench v1.5 上达到了 94.5% 的准确率,超越了之前的 SOTA 模型 PaddleOCR-VL。在表格、公式和文本识别方面观察到了显著提升。
-
现实5大场景文档解析的SOTA性能: 引入了一种创新的文档解析方法,支持不规则形状定位,能够在文档倾斜和弯曲条件下实现精确的多边形检测。在扫描、弯曲、倾斜、屏摄和光照变化这五个现实场景的评估中,表现优于主流的开源和闭源模型。
-
0.9B紧凑架构扩充能力: 模型引入了文本行定位与识别 以及 印章识别,所有相关指标均在各自任务中创下了新的 SOTA 结果。
-
强化多元素识别能力: PaddleOCR-VL-1.5 进一步增强了在特定场景和多语言识别方面的能力。针对特殊符号、古籍、多语言表格、下划线和复选框的识别性能得到提升,语言覆盖范围扩展至包括中国藏文和孟加拉语。
-
长文档跨页解析: 模型支持跨页表格自动合并和跨页段落标题识别,有效缓解了长文档解析中的内容碎片化问题。
二、技术架构¶
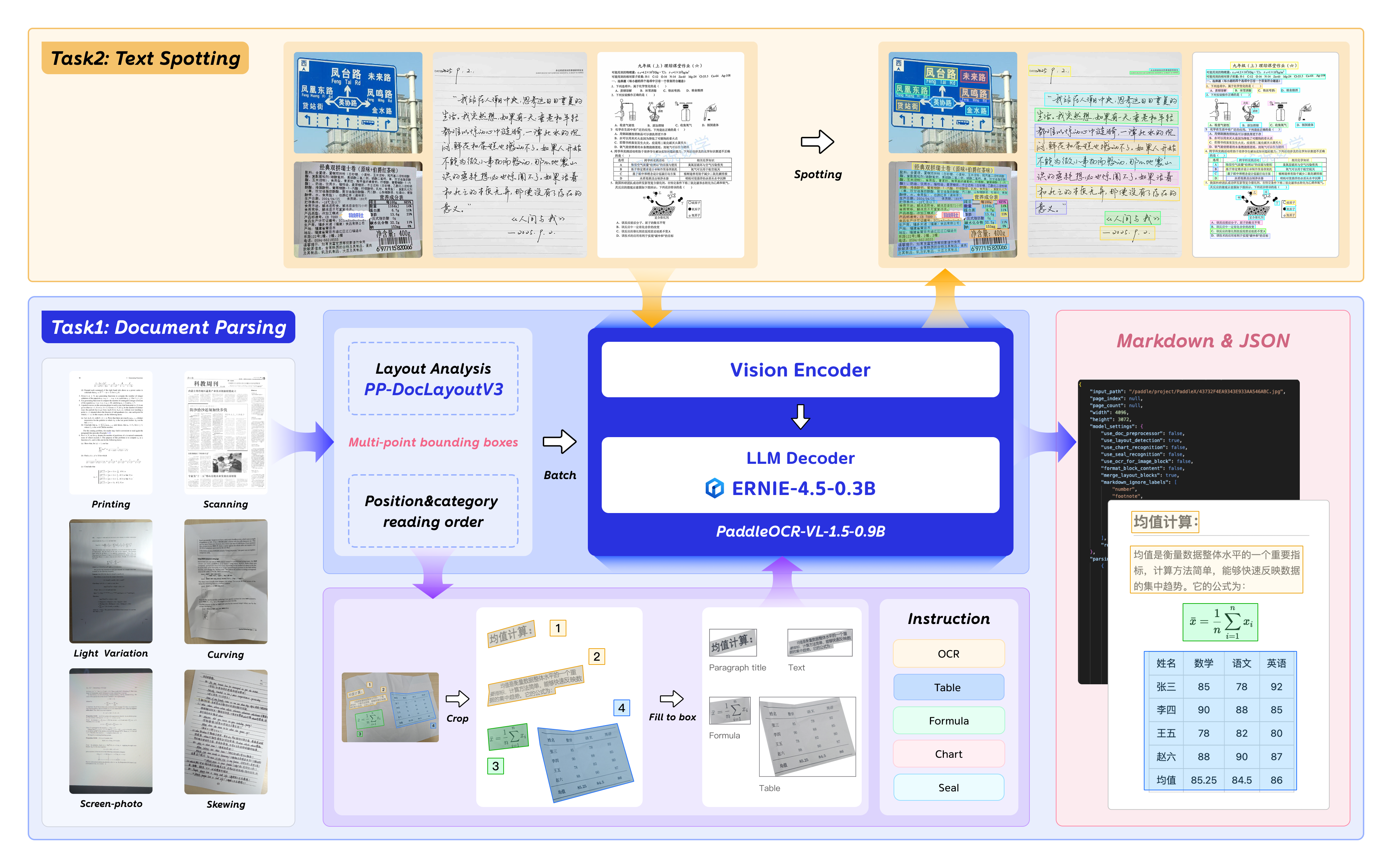
三、 模型性能¶
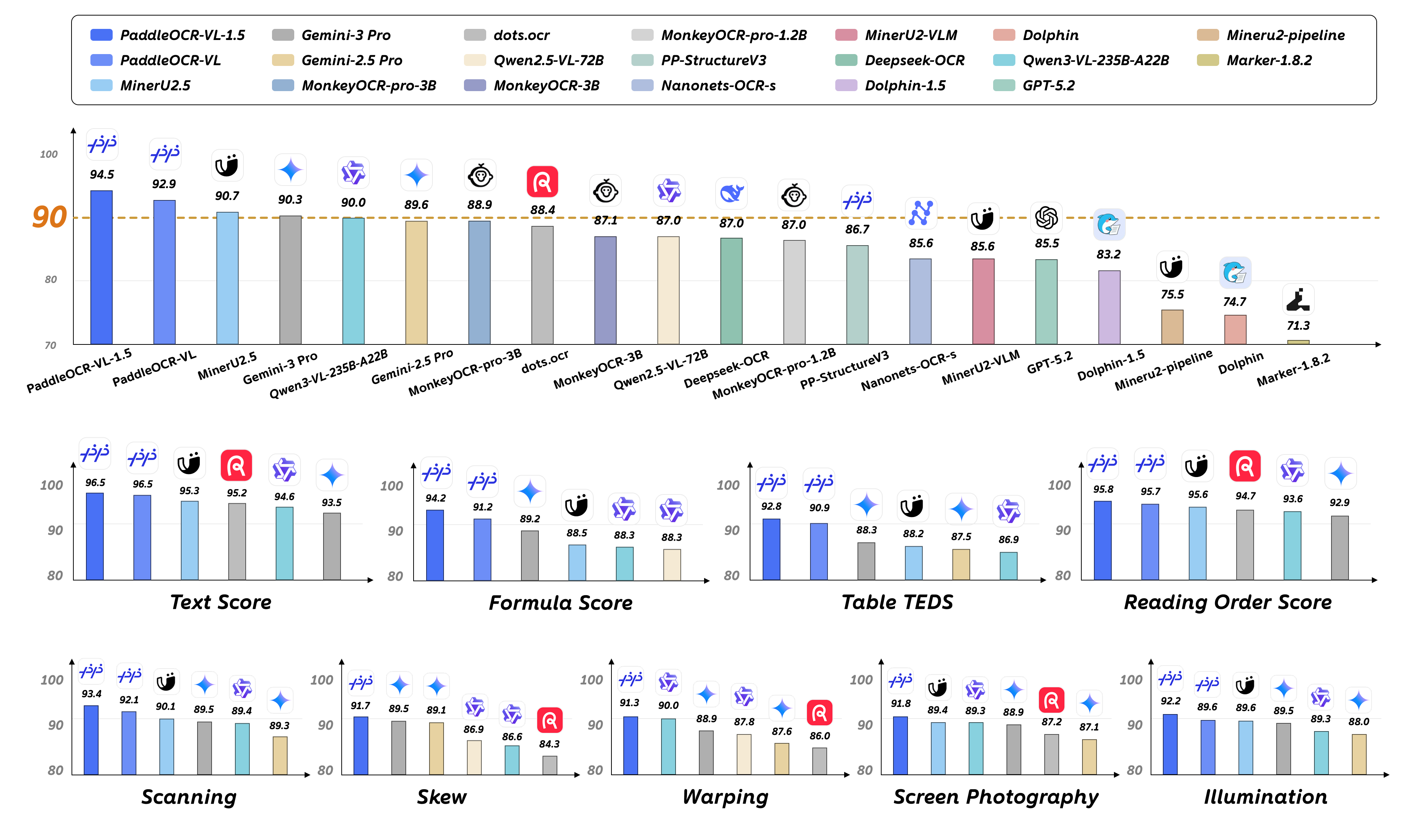
1. OmniDocBench v1.5¶
PaddleOCR-VL 在 OmniDocBench v1.5 上的整体、文本、公式、表格和阅读顺序中均达到最先进的性能。¶
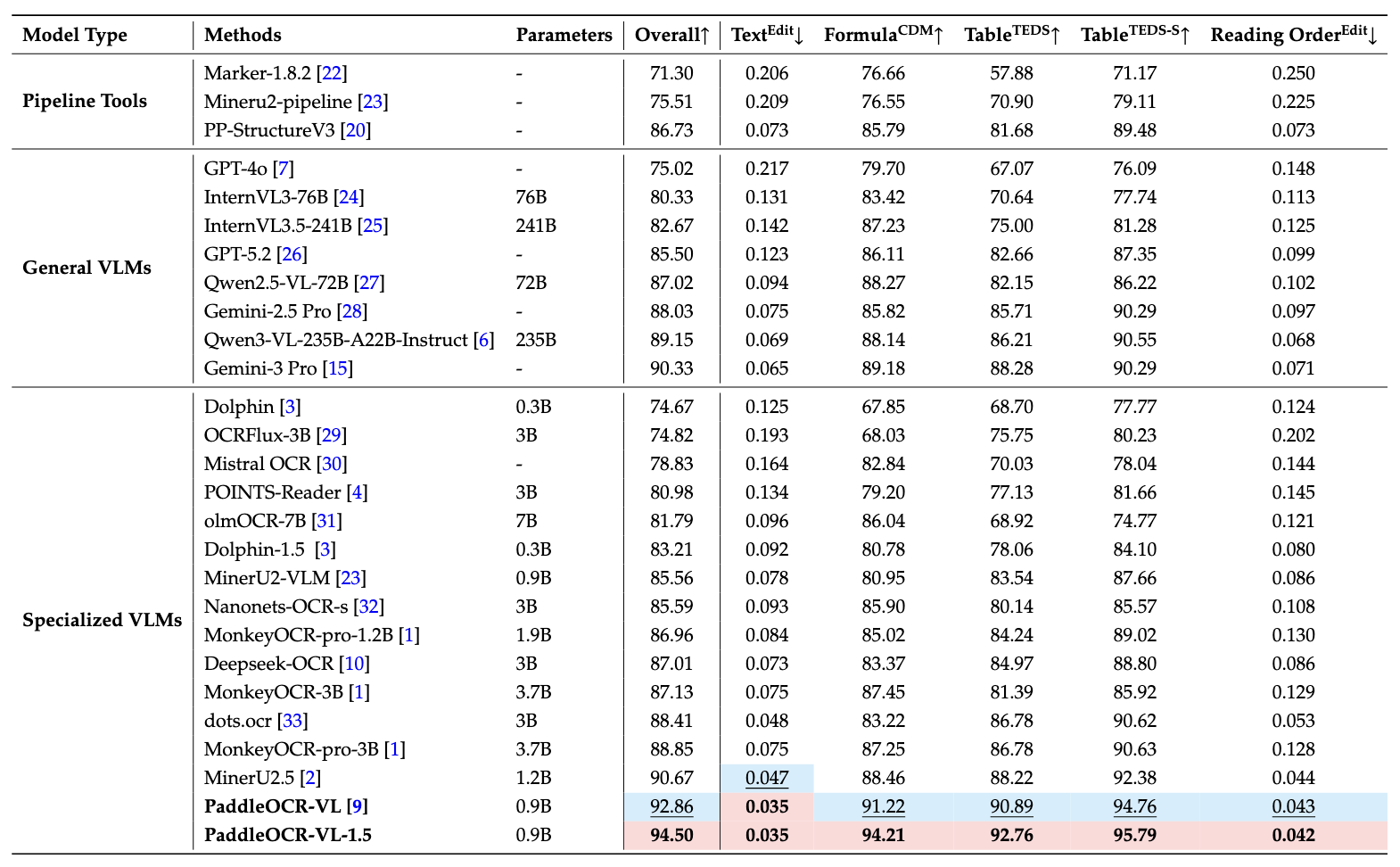
注: - 性能指标引自 OmniDocBench 官方排行榜, Gemini-3 Pro、Qwen3-VL-235B-A22B-Instruct 和我们的模型除外。
2. Real5-OmniDocBench¶
在扫描、扭曲、屏摄、光照和倾斜这五个多样化且具挑战性的场景中,PaddleOCR-VL-1.5 均创下了新的 SOTA 记录。¶
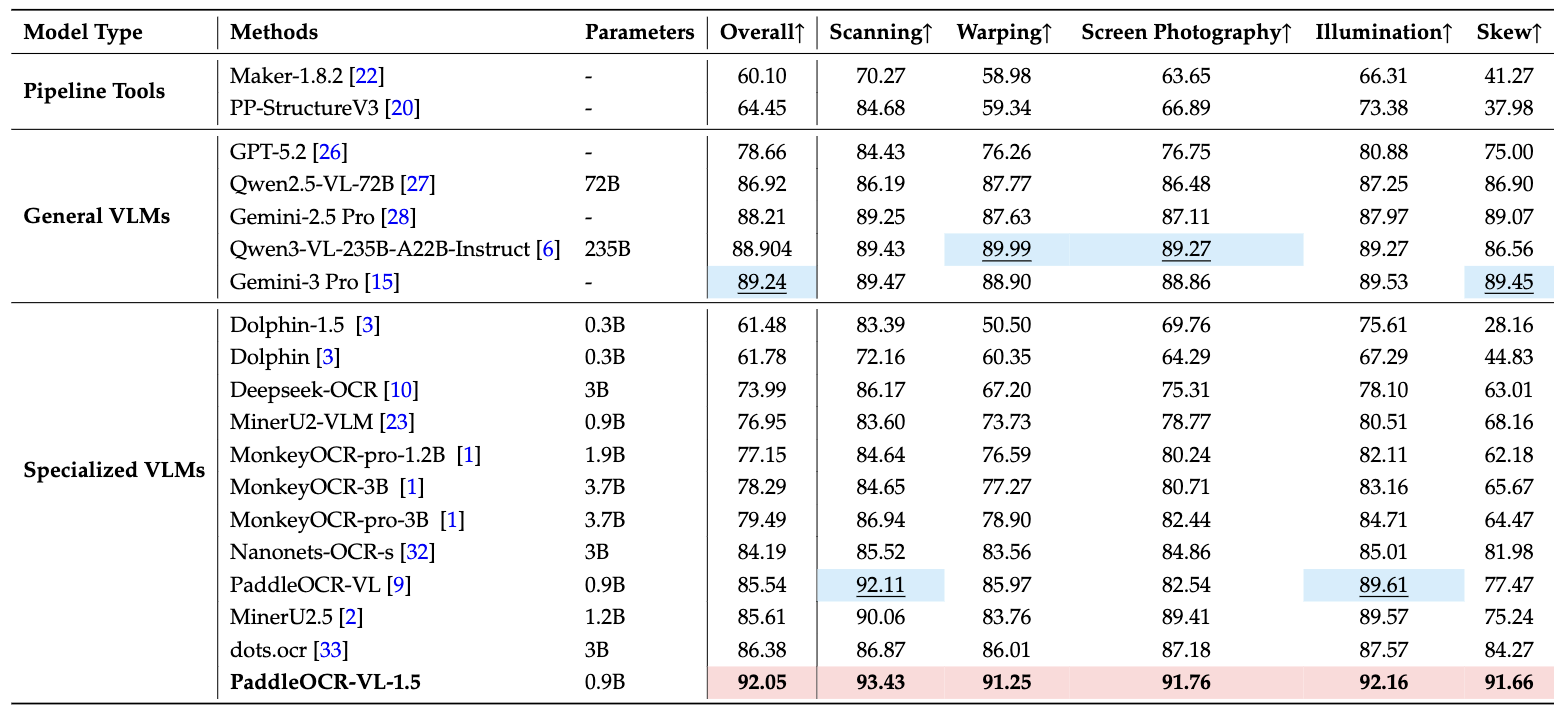
注: - Real5-OmniDocBench 是我们基于 OmniDocBench v1.5 数据集构建的、面向真实场景的全新基准测试。该数据集包含五个不同场景:扫描 (Scanning)、扭曲 (Warping)、屏摄 (Screen-photography)、光照 (Illumination) 和倾斜 (Skew)。更多详情请参阅 Real5-OmniDocBench.
4、推理部署性能¶
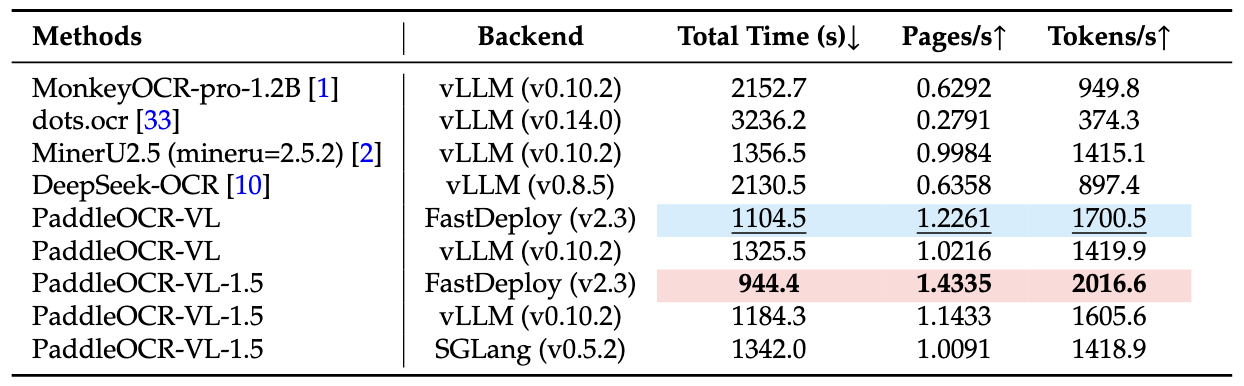
注: - OmniDocBench v1.5 上的端到端推理性能对比。PDF 文档在单张 NVIDIA A100 GPU 上以 512 的 batch size 进行处理。报告的端到端运行时间包含 PDF 渲染和 Markdown 生成。所有方法均依赖其内置的 PDF 解析模块和默认 DPI 设置,以反映开箱即用的性能。
5. 可视化¶
现实场景文档¶
光照¶

倾斜¶

屏摄¶

扫描¶

弯曲/扭曲¶

文本定位与识别¶

印章识别¶
