PaddleOCR-VL简介
一、PaddleOCR-VL简介¶
PaddleOCR-VL 是一款先进、高效的文档解析模型,专为文档中的元素识别设计。其核心组件为 PaddleOCR-VL-0.9B,这是一种紧凑而强大的视觉语言模型(VLM),它由 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型组成,能够实现精准的元素识别。该模型支持 109 种语言,并在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公开基准与内部基准上的全面评测,PaddleOCR-VL 在页级级文档解析与元素级识别均达到 SOTA 表现。它显著优于现有的基于Pipeline方案和文档解析多模态方案以及先进的通用多模态大模型,并具备更快的推理速度。这些优势使其非常适合在真实场景中落地部署。
关键指标:¶
核心特性:¶
-
紧凑而强大的视觉语言模型架构: 我们提出了一种新的视觉语言模型,专为资源高效的推理而设计,在元素识别方面表现出色。通过将NaViT风格的动态高分辨率视觉编码器与轻量级的ERNIE-4.5-0.3B语言模型结合,我们显著增强了模型的识别能力和解码效率。这种集成在保持高准确率的同时降低了计算需求,使其非常适合高效且实用的文档处理应用。
-
文档解析的SOTA性能: PaddleOCR-VL在页面级文档解析和元素级识别中达到了最先进的性能。它显著优于现有的基于流水线的解决方案,并在文档解析中展现出与领先的视觉语言模型(VLMs)竞争的强劲实力。此外,它在识别复杂的文档元素(如文本、表格、公式和图表)方面表现出色,使其适用于包括手写文本和历史文献在内的各种具有挑战性的内容类型。这使得它具有高度的多功能性,适用于广泛的文档类型和场景。
-
多语言支持: PaddleOCR-VL支持109种语言,覆盖了主要的全球语言,包括但不限于中文、英文、日文、拉丁文和韩文,以及使用不同文字和结构的语言,如俄语(西里尔字母)、阿拉伯语、印地语(天城文)和泰语。这种广泛的语言覆盖大大增强了我们系统在多语言和全球化文档处理场景中的适用性。
二、技术架构¶
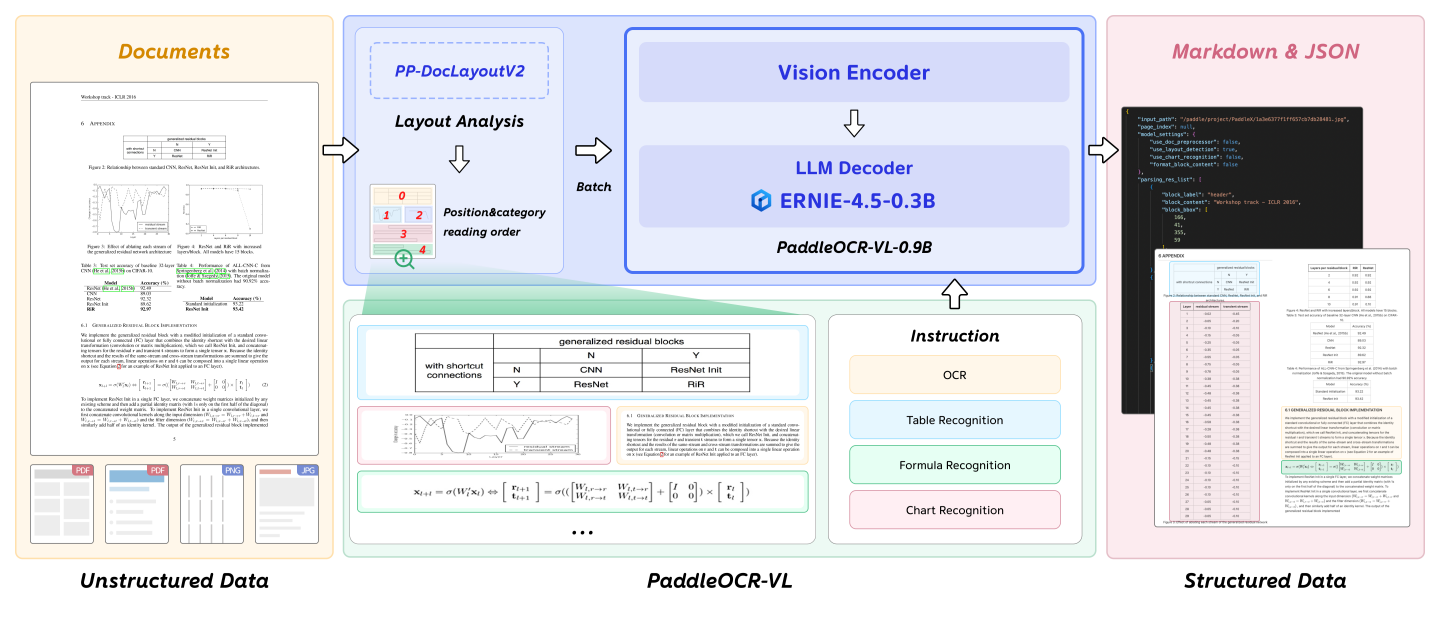
三、 模型性能¶
页面级文档解析¶
1. OmniDocBench v1.5¶
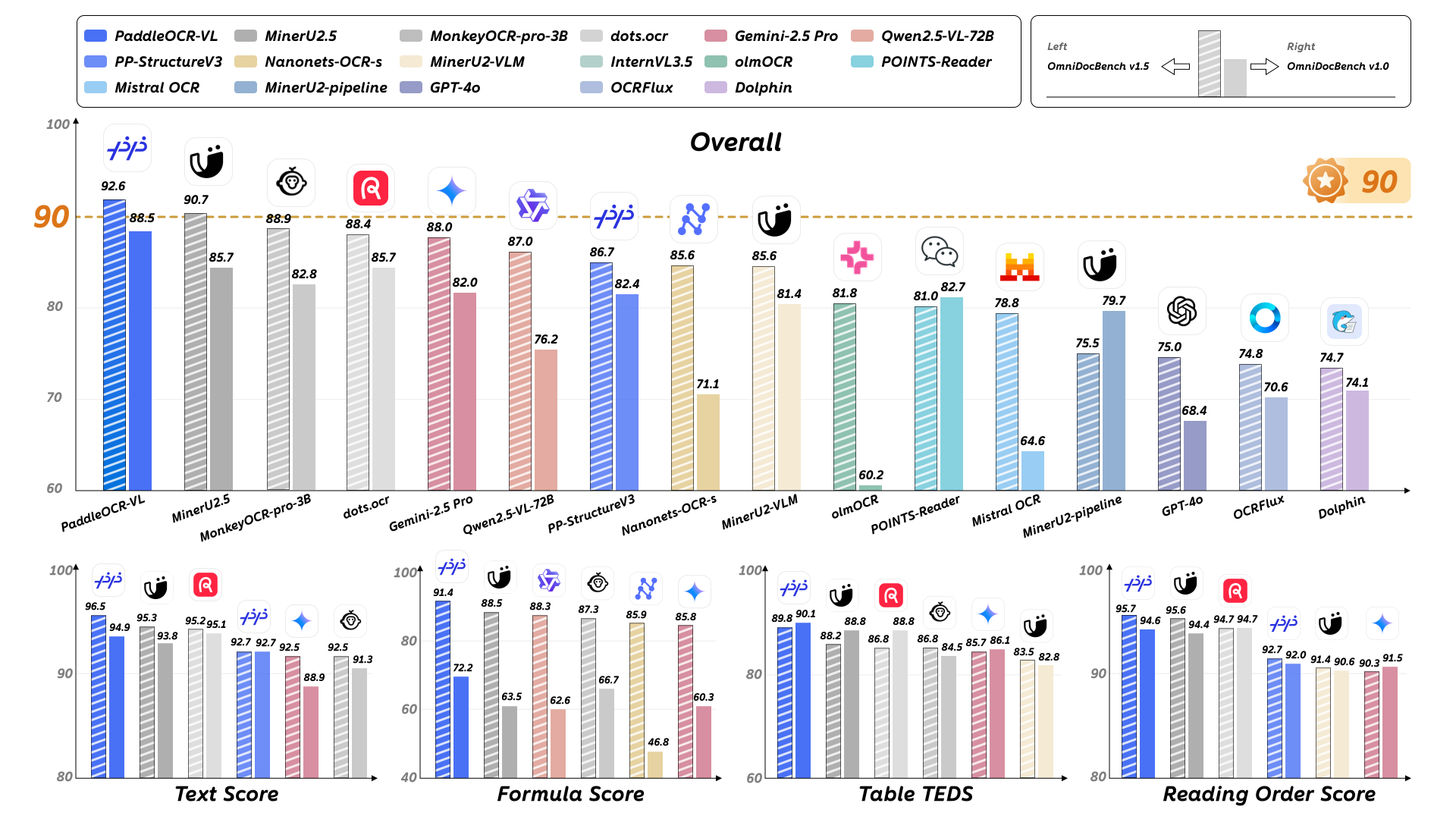
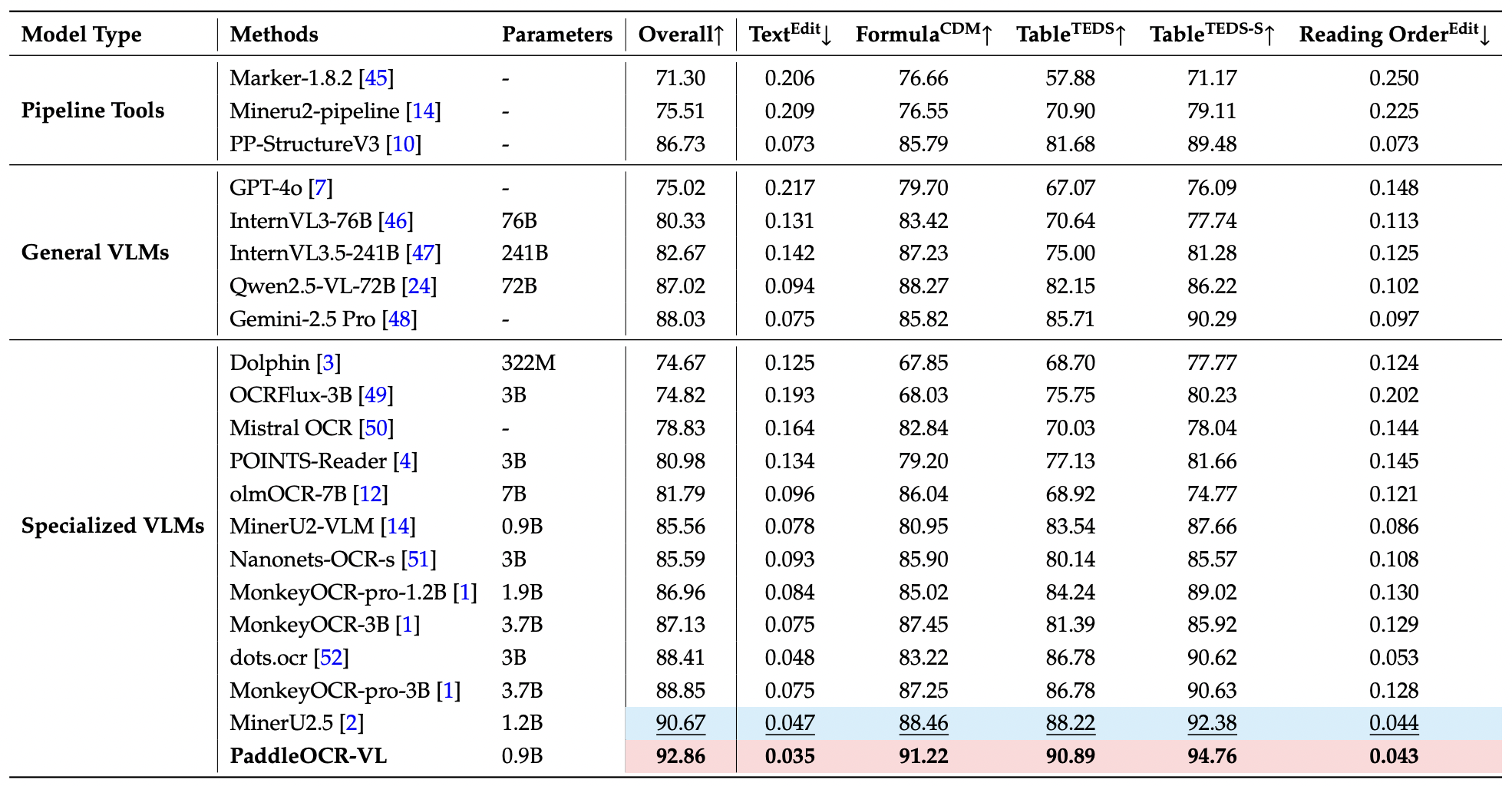
PaddleOCR-VL 在 OmniDocBench v1.5 上的整体、文本、公式、表格和阅读顺序中均达到最先进的性能。¶
2. OmniDocBench v1.0¶
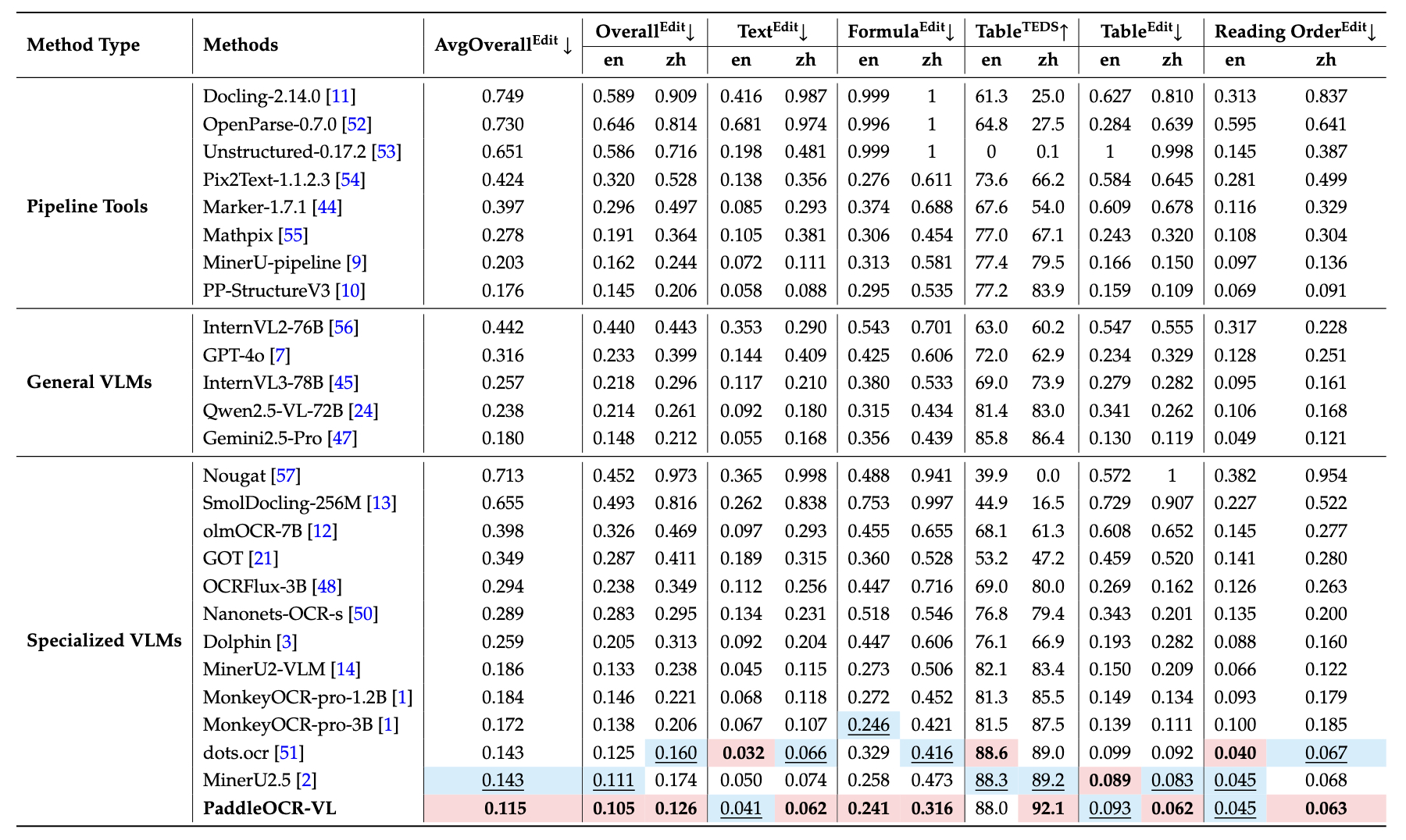
PaddleOCR-VL 在 OmniDocBench v1.0 的整体、文本、公式、表格以及阅读顺序等几乎所有评估指标上均达到了 SOTA 性能。¶
元素级识别¶
文本¶
OmniDocBench-OCR-block
PaddleOCR-VL 在处理多样化文档类型方面展现出强大而灵活的能力,使其在 OmniDocBench-OCR-block 的性能评估中成为领先方法。

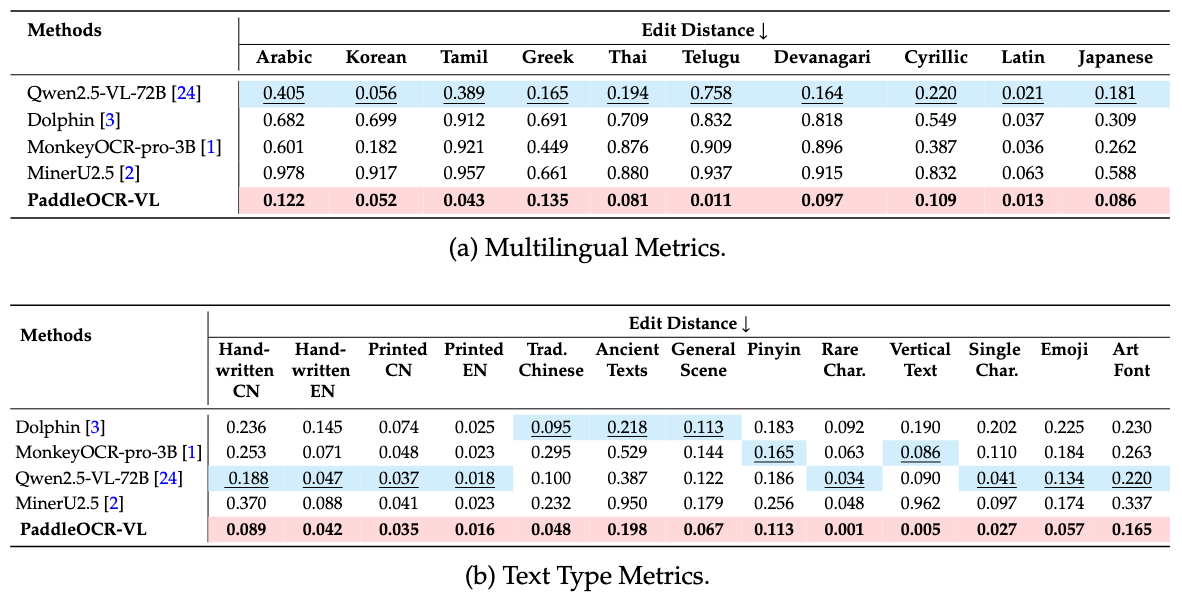
In-house-OCR-block
我们自建的评测集评估了模型在多语言和多文本类型下的性能。我们的模型在所有评测文字体系中均表现出卓越的准确性,并取得了最低的编辑距离。
表格¶
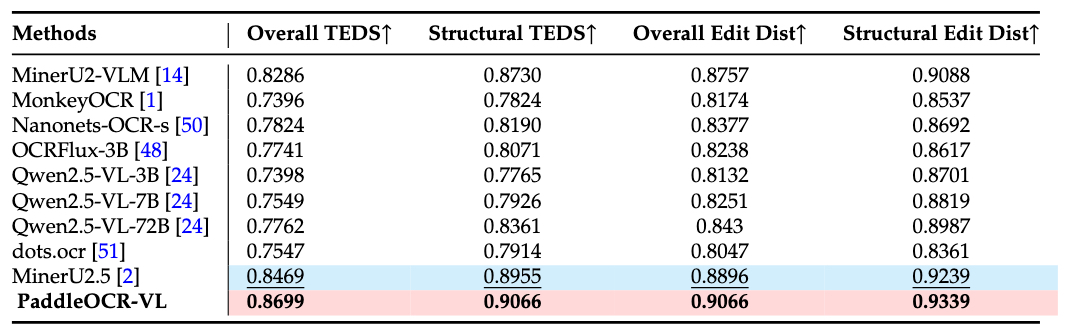
In-house-Table
我们自建的评测集包含多种类型的表格图像,例如中文、英文、中英混合表格,以及具有不同特征的表格类型,如完整边框、部分边框、无边框、书籍/手册格式、列表、学术论文表格、合并单元格等,还包括低质量和带水印的样本。PaddleOCR-VL 在所有类别中均展现出卓越的性能。
公式¶
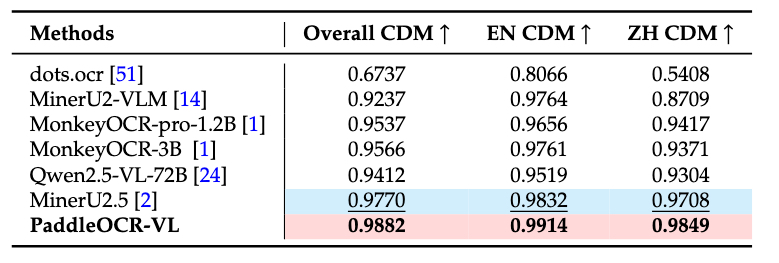
In-house-Formula
我们自建的评测集包含简单印刷、复杂印刷、摄像扫描以及手写公式等多种类型。PaddleOCR-VL 在所有类别中均取得了最佳性能。
图表¶
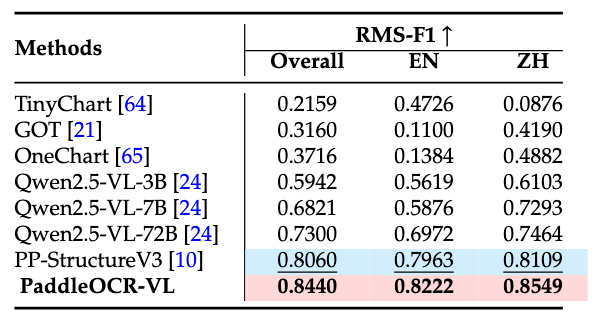
In-house-Chart 结果比较
我们自建的评测集涵盖 11 种主要图表类型,包括柱线混合图、饼图、100% 堆叠柱状图、面积图、柱状图、气泡图、直方图、折线图、散点图、堆叠面积图和堆叠柱状图。PaddleOCR-VL 不仅优于专业 OCR VLM 模型,还超越了一些 72B 级别的多模态语言模型。
四、推理部署性能¶
为了提升PaddleOCR-VL的推理性能,我们在推理工作流程中引入了多线程异步执行。该过程分为三个主要阶段:数据加载(例如,将PDF页面渲染为图像)、布局模型处理和VLM推理——每个阶段都在一个单独的线程中运行。数据通过队列在相邻阶段之间传输,从而实现并发执行以提高效率。在OmniDocBench v1.0数据集上测量了端到端推理速度和GPU使用情况,以512个PDF文件的批次在单个NVIDIA A100 GPU上进行处理。
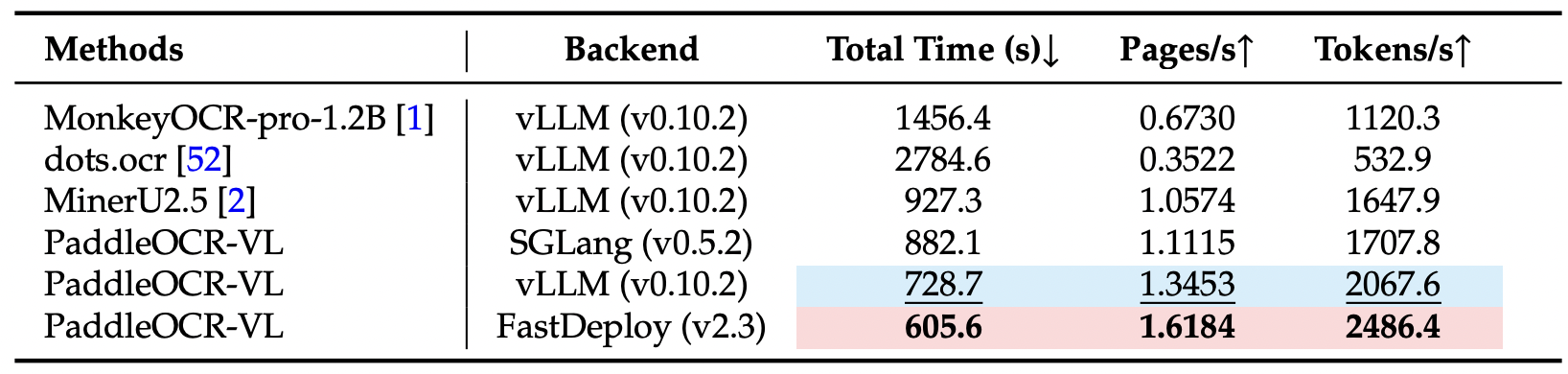
Notes: † 表示vLLM后端,‡ 表示SGLang后端
五、可视化¶
PaddleOCR-VL能够支持多种类型的文档解析,以下是一些预测案例的展示:
端到端文档解析¶




文本识别¶


表格识别¶
公式识别¶

图表识别¶

六、FAQ¶
1.如何使用 PaddleOCR-VL 做文档解析 ?
参考我们的使用文档 PaddleOCR-VL使用
2.如何对 PaddleOCR-VL 模型进行微调 ?
目前我们暂不支持模型的微调,但已经在高优的支持中,即将发布,请保持关注。
3.为什么我的图表没有识别出来,如何使用图表识别 ?
因为我们默认图表识别的功能是关闭的,需要手动开启,请参考 PaddleOCR-VL使用, 设置 use_chart_recognition为True 参数来开启。
4.支持的109种语言有哪些?
中文、英语、韩语、日语、泰语、希腊语、泰米尔语、泰卢固语
阿拉伯语:阿拉伯语、波斯语、维吾尔语、乌尔都语、普什图语、库尔德语、信德语、俾路支语
拉丁语:法语、德语、南非荷兰语、意大利语、西班牙语、波斯尼亚语、葡萄牙语、捷克语、威尔士语、丹麦语、爱沙尼亚语、爱尔兰语、克罗地亚语、乌兹别克语、匈牙利语、塞尔维亚语(拉丁语)、印度尼西亚语、奥克语、冰岛语、立陶宛语、毛利语、马来语、荷兰语、挪威语、波兰语、斯洛伐克语、斯洛文尼亚语、阿尔巴尼亚语、瑞典语、斯瓦希里语、他加禄语、土耳其语、拉丁语、阿塞拜疆语、库尔德语、拉脱维亚语、马耳他语、巴利语、罗马尼亚语、越南语、芬兰语、巴斯克语、加利西亚语、卢森堡语、罗曼什语、加泰罗尼亚语、盖丘亚语
西里尔文:俄语、白俄罗斯语、乌克兰语、塞尔维亚语(西里尔文)、保加利亚语、蒙古语、阿布哈兹语、阿迪杰语、卡巴尔达语、阿瓦尔语、达尔金语、印古什语、车臣语、拉克语、列兹金语、塔巴萨兰语、哈萨克语、吉尔吉斯语、塔吉克语、马其顿语、鞑靼语、楚瓦什语、巴什基尔语、马里语、摩尔多瓦语、乌德穆尔特语、科米语、奥塞梯语、布里亚特语、卡尔梅克语、图瓦语、萨哈语、卡拉卡尔帕克语
天城语:印地语、马拉地语、尼泊尔语、比哈里语、迈蒂利语、安吉卡语、博杰普里语、马基语、桑塔利语、纽瓦里语、康卡尼语、梵语、哈里亚维语
5.如果版面检测的结果不理想,有什么方案可以优化?
由于版面检测主要针对各种文档场景训练,所以您的测试数据如果是非标准文档,如车牌,火车票或身份证图像想做OCR识别,那可以直接使用PaddleOCR-VL-0.9B的模型,通过设置 use_layout_detection 为 False 关闭版面检测模型。如果您发现有任何版面检测的错误,都可以直接尝试一下单独使用PaddleOCR-VL-0.9B的效果。 我们推荐使用 ERNIEKit 套件 对 PaddleOCR-VL-0.9B 模型进行有监督微调(SFT)。具体操作步骤可参考 ERNIEKit 官方文档。