一、PP-OCRv6简介¶
PP-OCRv6 是 PP-OCR 最新一代通用文字识别解决方案。PP-OCRv6 基于全新设计的 PPLCNetV4 统一骨干网络,提供 tiny、small、medium 三档模型,分别面向端侧/IoT、移动端/桌面端、服务端场景。PP-OCRv6 在语言覆盖方面实现重大突破,medium/small 档单一模型统一支持简体中文、繁体中文、英文、日文及 46 种拉丁语系语言共 50 种语言(tiny 档支持 49 种,不含日文)。在内部多场景综合评估集上,PP-OCRv6_medium 相比 PP-OCRv5_server 识别精度提升 5.1%、检测精度提升 4.6%,同时 GPU 推理速度提升 2.37×;以仅 34.5M 参数的规模,精度超越 Qwen3-VL-235B、GPT-5.5 等大型视觉语言模型。
PP-OCRv6 的主要贡献如下:
- 统一可扩展的模型族:提供覆盖 1.5M 至 34.5M 参数的三档完整 OCR 模型族。medium 档达到 86.2% 检测 Hmean 和 83.2% 识别准确率,可作为工业部署和大规模数据管线的高效生产级基础设施。
- 面向 OCR 的轻量级架构创新:提出一系列专为 OCR 任务定制的轻量级架构组件——(i) LCNetV4:集成结构重参数化的 MetaFormer 风格轻量骨干;(ii) RepLKFPN:利用膨胀可重参数化深度卷积实现大感受野的检测颈部;(iii) EncoderWithLightSVTR:基于局部-全局注意力和加性跳跃连接的识别颈部。
- 广泛的多语言与多场景泛化:单一模型扩展至支持 50 种语言和多种挑战性工业场景(如数码显示屏、点阵字符、轮胎印字等),显著提升了传统通用视觉语言模型难以覆盖的专业场景 OCR 性能。
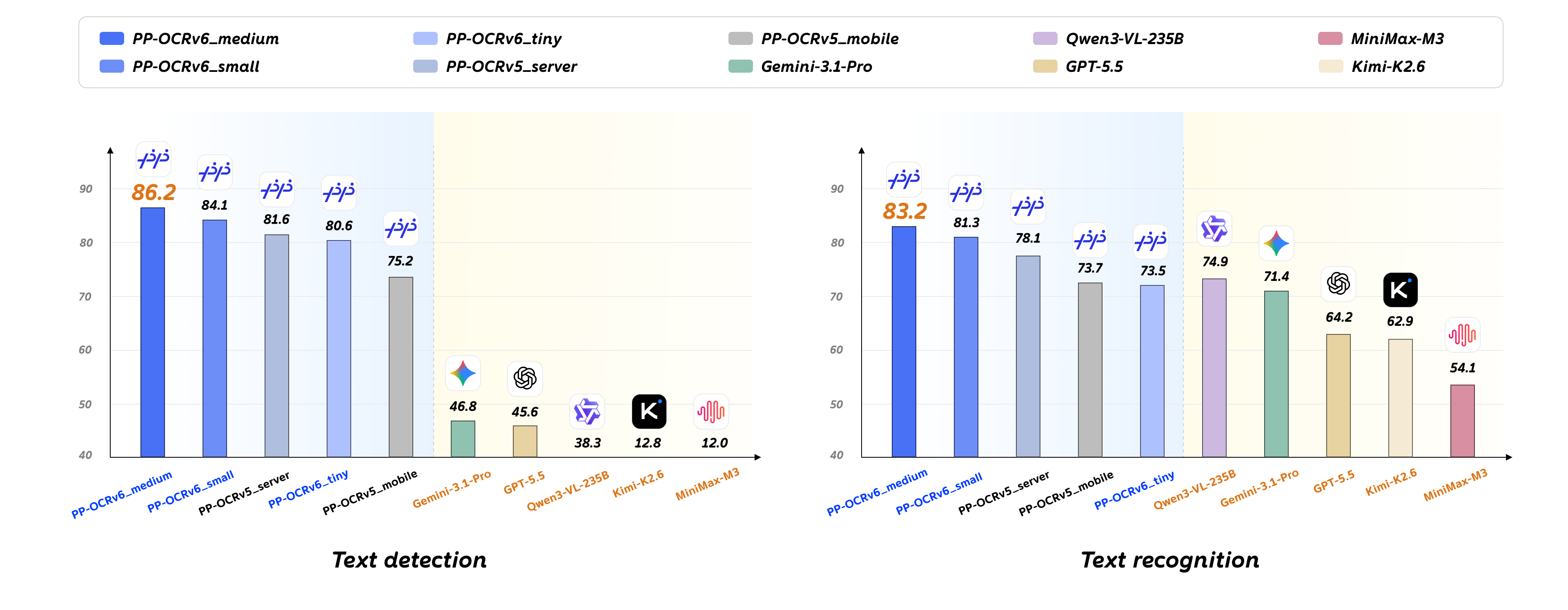
图:PP-OCRv6 与 PP-OCRv5 及视觉语言模型的性能对比。左:文本检测平均 Hmean(%);右:文本识别加权平均准确率(%)。
二、核心技术升级¶
1. 统一骨干网络 PPLCNetV4¶
PP-OCRv6 采用全新设计的 PPLCNetV4 作为检测和识别的统一骨干网络,核心创新包括:
LCNetV4Block:遵循 MetaFormer 范式,将每层解耦为 Token Mixer 和 Channel Mixer。设输入特征 \(\mathbf{x} \in \mathbb{R}^{C \times H \times W}\),Block 计算如下:
其中 \(\text{DW}(\cdot)\) 是 3×3 深度卷积(Token Mixer),SE 是可选的通道注意力模块,\(W_1 \in \mathbb{R}^{2C \times C}\)、\(W_2 \in \mathbb{R}^{C \times 2C}\) 构成扩展比为 2 的 Channel Mixer,\(\sigma\) 为 GELU 激活。
Task-Adaptive Downsampling:同一骨干通过不同下采样策略服务两个任务——检测模式使用标准 stride-2 空间下采样产出多尺度特征图(stride 4/8/16/32);识别模式在 Stage 3/4 使用非对称 stride \((2,1)\),仅缩减高度保留宽度,经 height-axis 平均池化后产出 1-D 序列特征用于 CTC/NRTR 解码。
与 LCNetV3 对比:
| 设计维度 | LCNetV3 | LCNetV4 |
|---|---|---|
| 架构范式 | MobileNet-style (DW→SE→PW) | MetaFormer (TokenMixer + ChannelMixer) |
| 通道交互 | 单个 1×1 PW Conv | Expand(2×)→Act→Compress + 残差 |
| 空间混合 | 普通 DW Conv | RepDWConv(3×3 + 1×1 + identity 三分支) |
| BN 初始化 | 标准 | Compress 层 BN 零初始化 |
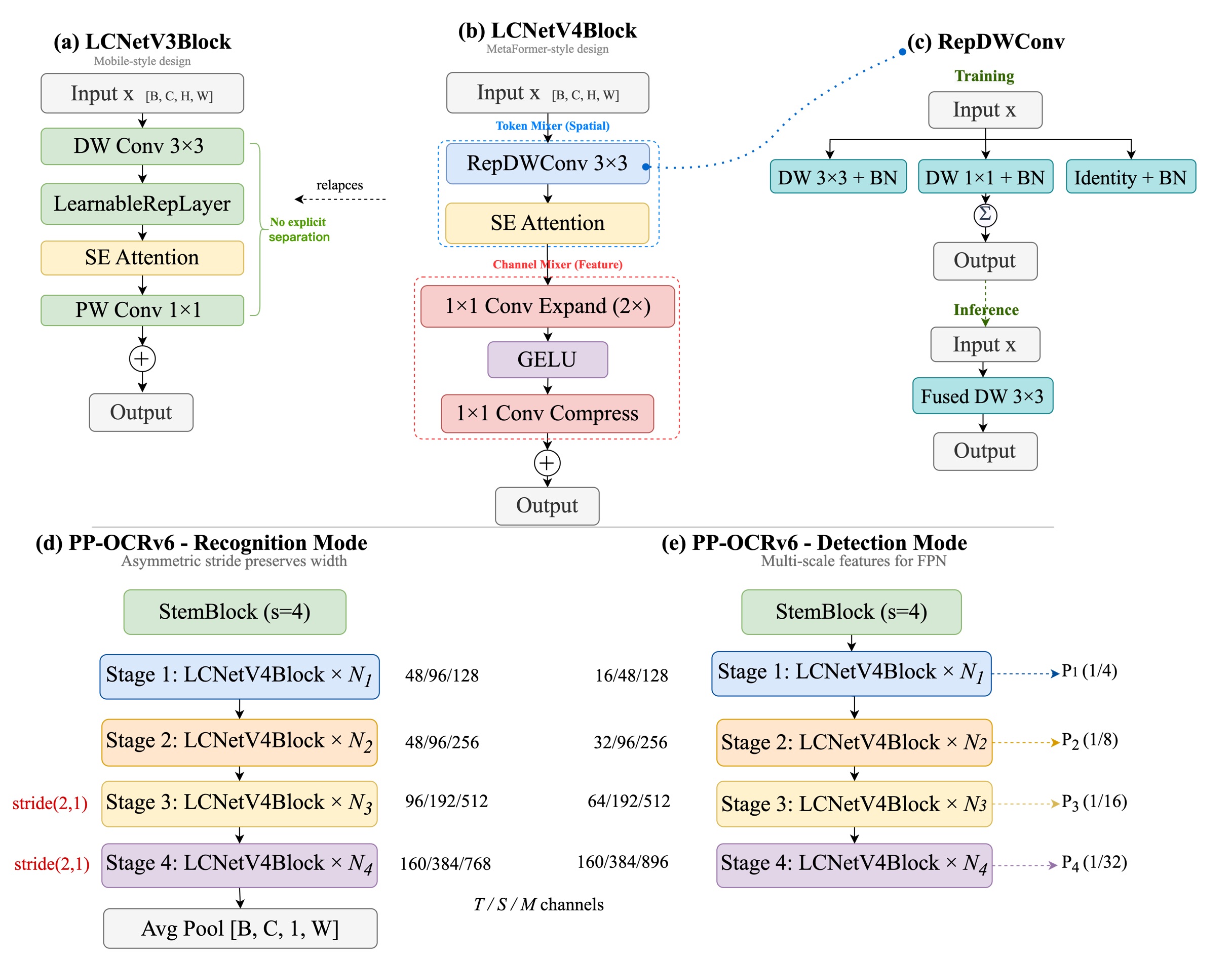
图:PPLCNetV4 骨干网络结构
2. 检测模块升级¶
- RepLKFPN:轻量级大核特征金字塔,使用 DilatedReparamBlock(7×7 深度卷积 + 膨胀分支),相比 PP-OCRv5 的 RSEFPN 参数减少 31%(118K vs 172K),同时感受野从 3×3 扩大到 7×7。
- 辅助深度监督:在 P2、P3、P4 层级添加预测头,训练时提供更强梯度信号。
- DiceBCE Loss:组合 DiceLoss + Focal Loss,对小目标和密集文本提供更好的逐像素监督。
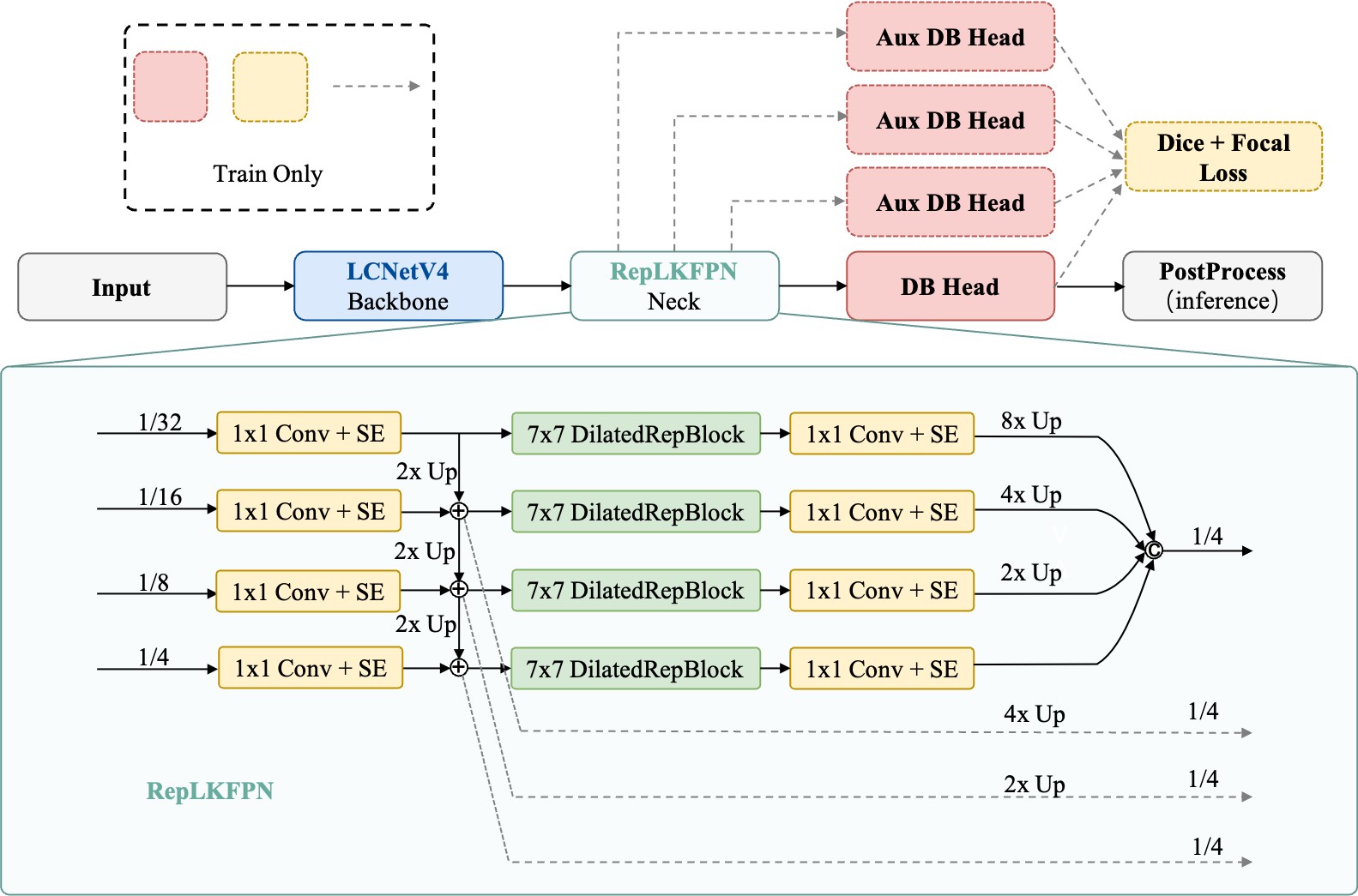
图:PP-OCRv6 检测模块结构
3. 识别模块升级¶
- EncoderWithLightSVTR 颈部:局部上下文建模(1×7 深度卷积)+ 全局自注意力(1-2 层 Transformer),通过加性跳跃连接(而非 PP-OCRv5 的拼接)减少参数。
- 多头解码器:CTCHead 用于高效并行推理,NRTRHead 用于训练时辅助监督(推理时移除)。
- Tiny 模型特殊设计:无颈部(直接 reshape + FC),使用 medium 模型蒸馏训练。
- 多语言统一:字典扩展约 200 个带变音符号字符,实现单模型 48 语言覆盖。
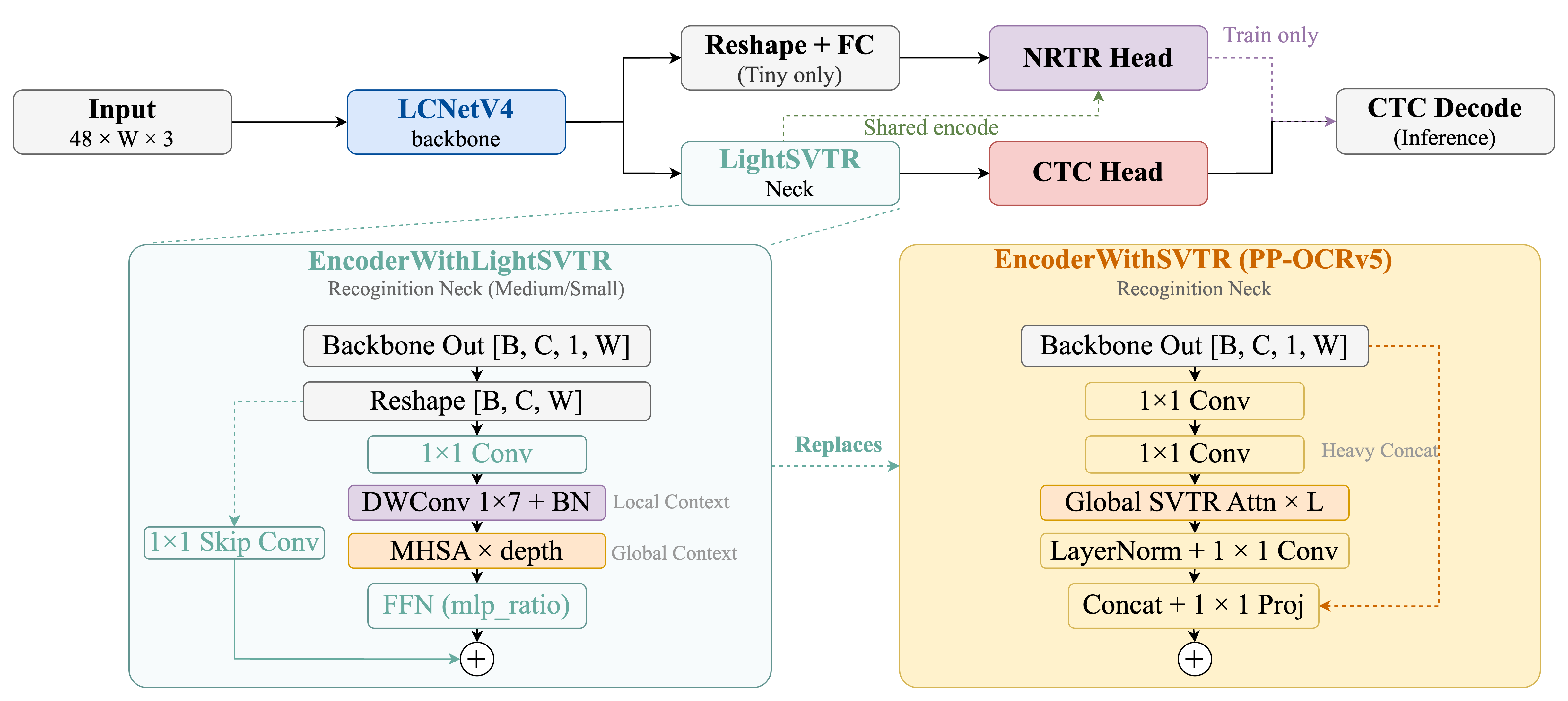
图:PP-OCRv6 识别模块结构
三、关键指标¶
1. 文本检测指标¶
在内部多场景基准上对 16 类场景进行文本检测 Hmean(%) 评测:
| 模型 | AVG | 手写CN | 手写EN | 印刷CN | 印刷EN | 繁体 | 古籍 | 日文 | 模糊 | 表情 | 扭曲 | 拼音 | 艺术字 | 表格 | 旋转 | 工业 | 通用 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv6_medium | 86.2 | 83.7 | 84.0 | 95.1 | 93.7 | 86.3 | 80.2 | 84.3 | 94.1 | 99.6 | 88.6 | 74.0 | 69.0 | 96.8 | 93.8 | 73.3 | 82.8 |
| PP-OCRv6_small | 84.1 | 80.5 | 87.1 | 94.2 | 93.6 | 85.7 | 72.6 | 82.3 | 92.6 | 99.7 | 87.6 | 69.6 | 65.3 | 95.6 | 93.7 | 67.6 | 78.2 |
| PP-OCRv6_tiny | 80.6 | 79.4 | 85.9 | 93.1 | 92.3 | 83.7 | 63.0 | 76.6 | 89.3 | 99.8 | 86.1 | 59.0 | 60.1 | 94.7 | 91.0 | 62.0 | 73.8 |
| PP-OCRv5_server | 81.6 | 80.3 | 84.1 | 94.5 | 91.7 | 81.5 | 67.6 | 77.2 | 90.1 | 96.2 | 87.6 | 67.1 | 67.3 | 97.1 | 80.0 | 64.3 | 79.7 |
| PP-OCRv5_mobile | 75.2 | 74.4 | 77.7 | 90.5 | 91.0 | 82.3 | 58.1 | 72.7 | 87.4 | 93.6 | 82.7 | 57.5 | 52.5 | 92.8 | 64.7 | 52.8 | 72.1 |
| Gemini-3.1-Pro | 46.8 | 53.4 | 56.5 | 47.3 | 47.6 | 39.0 | 45.8 | 38.2 | 50.0 | 68.1 | 44.6 | 40.6 | 65.2 | 26.9 | 22.1 | 52.5 | 50.2 |
| GPT-5.5 | 45.6 | 42.4 | 58.5 | 50.2 | 51.9 | 35.0 | 26.7 | 42.0 | 49.1 | 97.5 | 37.7 | 36.3 | 52.0 | 71.0 | 10.0 | 36.2 | 32.6 |
| Qwen3-VL-235B | 38.3 | 56.5 | 66.0 | 41.7 | 37.0 | 19.3 | 13.1 | 27.0 | 38.5 | 81.2 | 28.5 | 33.0 | 68.3 | 19.6 | 2.1 | 48.4 | 32.3 |
PP-OCRv6_medium 平均 Hmean 达 86.2%,相比 PP-OCRv5_server 提升 4.6 个百分点,在日文、古籍、旋转文本、工业字符等场景提升尤为显著。
2. 文本识别指标¶
在内部多场景基准上对 15 类场景进行文本识别准确率(%) 评测:
| 模型 | W-Avg | 手写CN | 手写EN | 印刷CN | 印刷EN | 繁体 | 古籍 | 日文 | 易混淆 | 特殊字符 | 通用 | 拼音 | 艺术字 | 工业 | 屏幕 | 卡片 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv6_medium | 83.2 | 62.1 | 67.8 | 91.5 | 94.1 | 78.6 | 72.4 | 90.5 | 64.9 | 61.7 | 87.5 | 78.1 | 71.2 | 77.4 | 82.5 | 88.1 |
| PP-OCRv6_small | 81.3 | 57.6 | 61.1 | 90.5 | 93.3 | 77.0 | 71.1 | 88.2 | 64.1 | 60.2 | 85.7 | 75.9 | 68.4 | 76.4 | 79.7 | 86.9 |
| PP-OCRv6_tiny | 73.5 | 40.1 | 39.3 | 86.7 | 88.4 | 65.0 | 68.4 | 89.8 | 52.3 | 57.1 | 78.0 | 65.4 | 54.7 | 62.1 | 71.2 | 80.5 |
| PP-OCRv5_server | 78.1 | 58.0 | 59.6 | 90.1 | 85.1 | 74.7 | 60.4 | 73.7 | 59.4 | 56.8 | 86.5 | 74.4 | 64.0 | 70.2 | 68.1 | 87.6 |
| PP-OCRv5_mobile | 73.7 | 41.7 | 50.9 | 86.0 | 86.0 | 72.0 | 57.8 | 75.8 | 55.7 | 54.8 | 80.7 | 72.5 | 54.0 | 59.3 | 57.6 | 81.7 |
| Qwen3-VL-235B | 74.9 | 49.7 | 73.2 | 82.3 | 86.2 | 76.4 | 33.6 | 66.2 | 56.1 | 49.0 | 82.5 | 76.5 | 69.6 | 74.7 | 73.8 | 78.7 |
| Gemini-3.1-Pro | 71.4 | 46.4 | 73.0 | 80.0 | 90.5 | 69.5 | 18.0 | 67.2 | 54.4 | 50.3 | 74.6 | 75.9 | 63.1 | 69.1 | 73.2 | 75.9 |
| GPT-5.5 | 64.2 | 19.2 | 56.9 | 75.7 | 82.2 | 57.5 | 63.7 | 58.6 | 49.1 | 48.3 | 67.7 | 50.4 | 53.0 | 62.4 | 67.7 | 71.1 |
PP-OCRv6_medium 加权平均准确率 83.2%,相比 PP-OCRv5_server 提升 5.1%,在日文(+16.8%)、古籍(+12.0%)、屏幕显示(+14.4%) 等类别提升显著。即使是仅 1.1M 参数的 PP-OCRv6_tiny,也超越了 4/5 的 VLM 模型。
4. 端到端推理速度(s/image)¶
在 200 张图像(通用场景 + 文档场景)上测试端到端 OCR 产线速度,包含读图、前后处理、模型推理全流程。
| 硬件 | 推理后端 | PP-OCRv6_medium | PP-OCRv6_small | PP-OCRv6_tiny | PP-OCRv5_server | PP-OCRv5_mobile | PP-OCRv4_mobile |
|---|---|---|---|---|---|---|---|
| NVIDIA A100 | PaddlePaddle | 0.29 | 0.25 | 0.13 | 0.32 | 0.25 | 0.14 |
| NVIDIA A100 | TensorRT | -- | 0.32 | 0.16 | -- | 0.33 | 0.16 |
| NVIDIA V100 | PaddlePaddle | 0.72 | 0.49 | 0.21 | 0.66 | 0.50 | 0.25 |
| NVIDIA V100 | ONNX Runtime | 0.67 | 0.53 | 0.29 | 0.77 | 0.46 | 0.27 |
| NVIDIA V100 | TensorRT | 0.77 | 0.60 | 0.23 | 0.73 | 0.59 | 0.27 |
| Intel Xeon 8350C | PaddlePaddle | 2.05 | 0.79 | 0.32 | 2.04 | 0.80 | 0.62 |
| Intel Xeon 8350C | OpenVINO | 1.40 | 0.59 | 0.20 | 7.30 | 0.78 | 0.60 |
| Intel Xeon 8350C | ONNX Runtime | 3.31 | 0.61 | 0.22 | 6.36 | 0.61 | 0.49 |
| Apple M4 | PaddlePaddle | 8.82 | 3.07 | 0.96 | >10 | 5.82 | 5.65 |
| Apple M4 | ONNX Runtime | 5.55 | 1.29 | 0.35 | 7.20 | 1.10 | 1.02 |
- PP-OCRv6_medium 在所有平台上均匹配或优于 PP-OCRv5_server:A100 上快 1.1×(0.29s vs 0.32s),V100 ONNX Runtime 快 1.15×(0.67s vs 0.77s),Intel Xeon OpenVINO 快 5.2×(1.40s vs 7.30s)。
- PP-OCRv6_small 在大多数平台上与 PP-OCRv5_mobile 速度持平但精度更高;Apple M4 PaddlePaddle 快 1.9×(3.07s vs 5.82s)。
- PP-OCRv6_tiny 是所有平台上最快的模型,Apple M4 PaddlePaddle 快 6.1×(0.96s vs 5.82s),Intel Xeon OpenVINO 快 3.9×(0.20s vs 0.78s),A100 上仅需 0.13s。
四、语言支持¶
PP-OCRv6 medium/small 档支持以下 50 种语言:
核心语言:简体中文、繁体中文、英文、日文
拉丁语系(46种):法文、德文、意大利文、西班牙文、葡萄牙文、荷兰文、波兰文、罗马尼亚文、捷克文、瑞典文、挪威文、丹麦文、芬兰文、匈牙利文、土耳其文、越南文、印尼文、马来文、阿塞拜疆文、南非荷兰文、波斯尼亚文、克罗地亚文、威尔士文、爱沙尼亚文、爱尔兰文、冰岛文、库尔德文、立陶宛文、拉脱维亚文、马耳他文、毛利文、奥克文、斯洛伐克文、斯洛文尼亚文、阿尔巴尼亚文、斯瓦希里文、他加禄文、乌兹别克文、拉丁文、塞尔维亚文(拉丁)、加泰罗尼亚文、巴斯克文、加利西亚文、卢森堡文、罗曼什文、克丘亚文
PP-OCRv6_tiny 档支持 49 种语言(不含日文,以避免约 4000 个汉字/假名字符对 1.1M 参数输出层的影响)。
五、效果可视化¶
1. 检测效果对比¶

图:文本检测效果对比。从左到右:PP-OCRv6_medium、PP-OCRv5_server、Gemini-3.1-Pro、GPT-5.5。
2. 幻觉对比¶

图:PP-OCRv6_medium 与 VLM 的幻觉对比。PP-OCRv6 忠实还原图像中的文字内容,而 VLM 基于语言先验进行"纠正",引入了图像中不存在的幻觉。
3. 端到端 OCR 效果对比¶
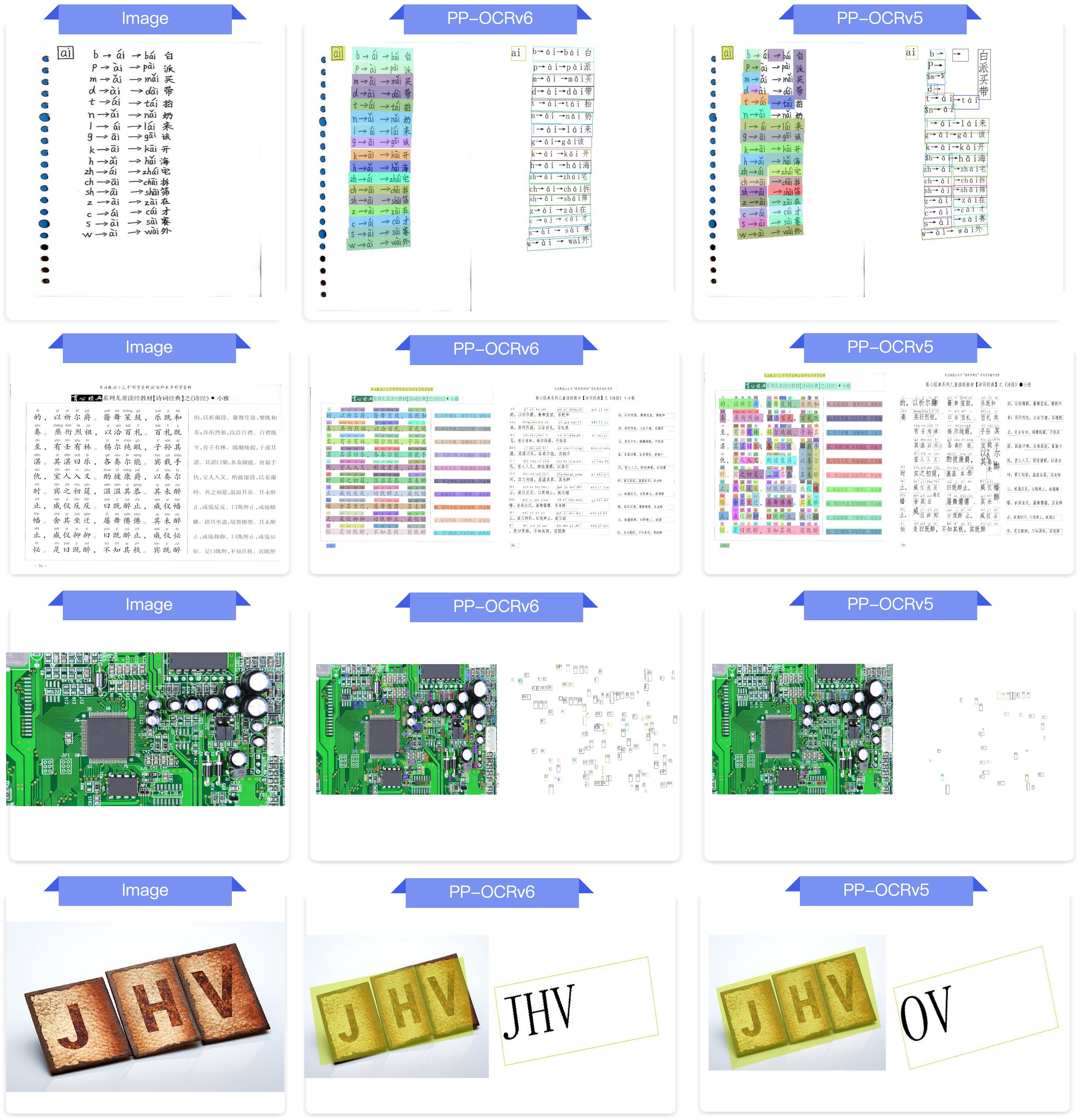
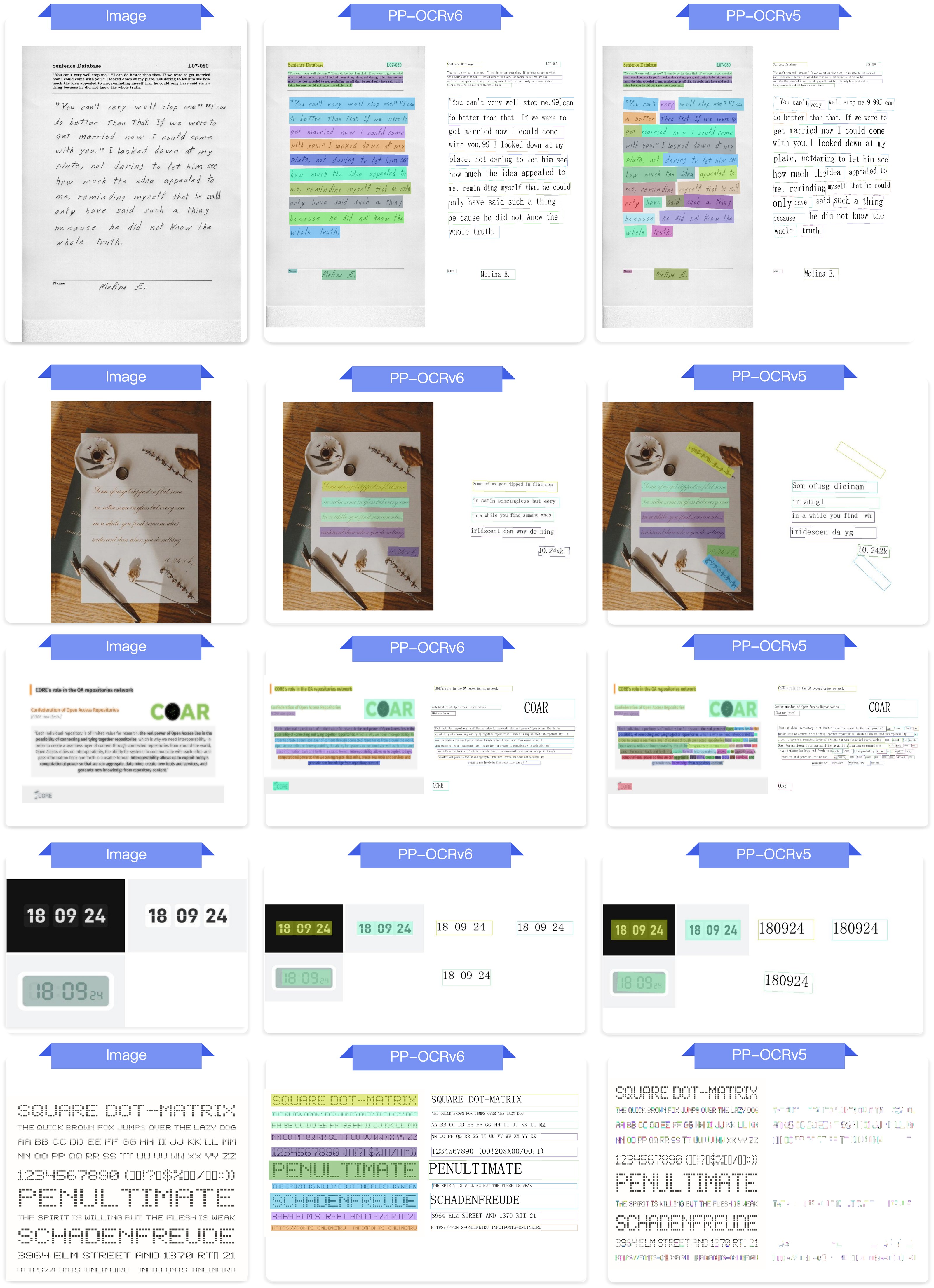
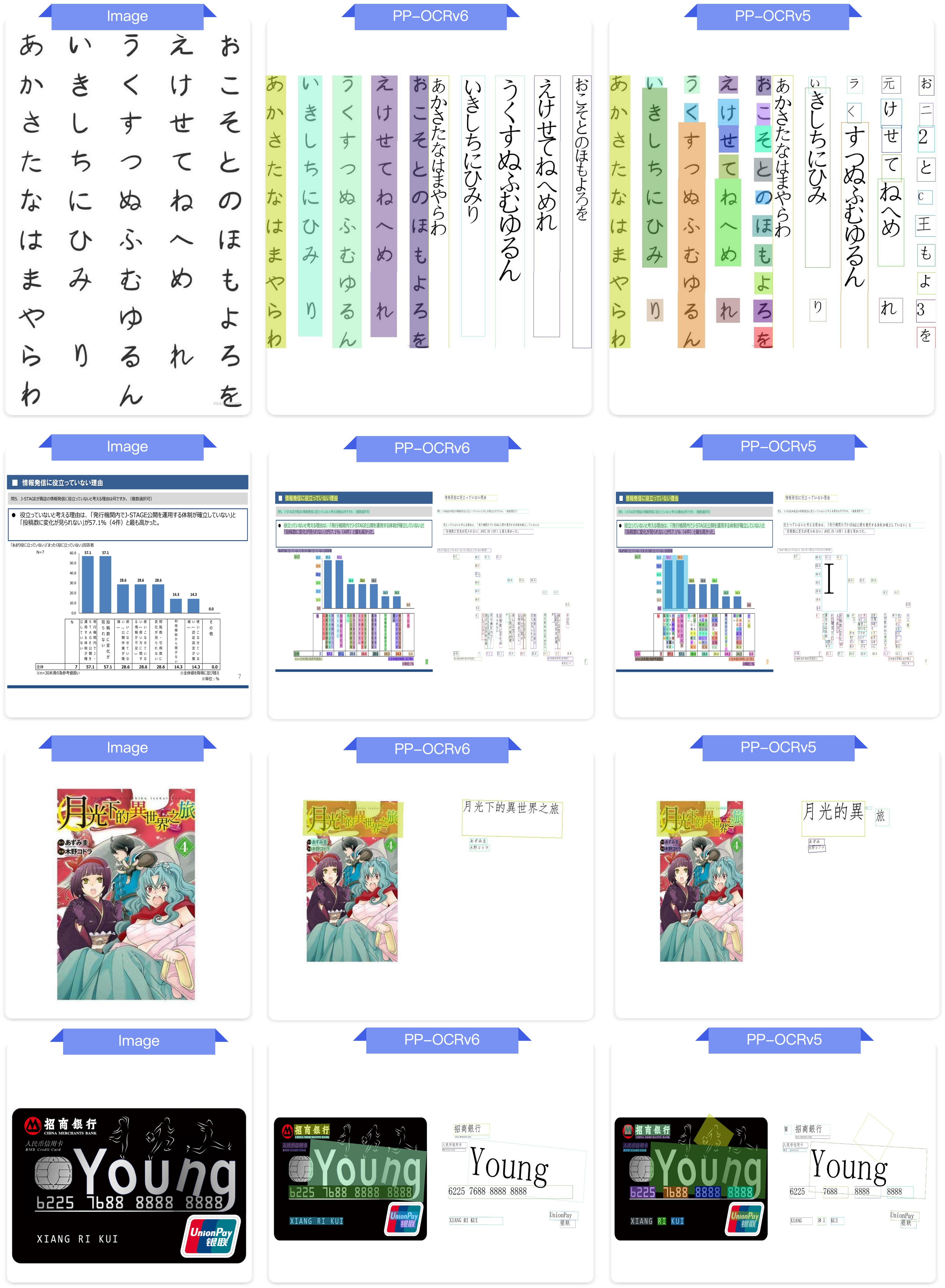
图:PP-OCRv6_medium 与 PP-OCRv5_server 端到端 OCR 效果对比,涵盖中文、英文、日文、艺术字、工业字符、旋转文本、拼音、点阵字符等场景。
六、快速使用¶
from paddleocr import PaddleOCR
# 默认使用 PP-OCRv6_medium
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
result = ocr.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
# 命令行使用
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False
使用 Transformers 引擎推理:
PP-OCRv6 支持通过 Hugging Face Transformers 引擎进行推理(需安装 transformers>=5.8.0):
from paddleocr import TextRecognition
model = TextRecognition(
model_name="PP-OCRv6_medium_rec",
engine="transformers",
)
output = model.predict(input="general_ocr_rec_001.png", batch_size=1)
for res in output:
res.print()
# 命令行方式
paddleocr text_recognition -i general_ocr_rec_001.png \
--text_recognition_model_name PP-OCRv6_medium_rec \
--engine transformers
使用高性能推理(ONNX Runtime 后端):
通过 enable_hpi=True 启用高性能推理插件,底层会自动使用 ONNX Runtime 加速:
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
enable_hpi=True,
)
result = ocr.predict("general_ocr_002.png")
# 命令行方式
paddleocr ocr -i general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False \
--enable_hpi True
高性能推理插件需额外安装,详见高性能推理指南。
七、部署与二次开发¶
- 多系统支持:兼容 Windows、Linux、Mac 等主流操作系统。
- 多硬件支持:支持英伟达 GPU、Intel CPU、昆仑芯、昇腾等硬件推理和部署。
- 高性能推理插件:推荐结合高性能推理插件进一步提升推理速度,详见高性能推理指南。
- 服务化部署:支持高稳定性服务化部署方案,详见服务化部署指南。
- 二次开发能力:支持自定义数据集训练、字典扩展、模型微调,详见文本检测模块使用教程及文本识别模块使用教程。