X-AnyLabeling 文档解析¶
简介¶
PaddleOCR-VL 系列模型的文档解析能力已集成至 X-AnyLabeling 标注平台。
X-AnyLabeling 是由 CVHub 推出的工业级一体化智能标注平台,打通训练、推理、标注全链路。借助其 PaddleOCR 面板,开发者可以基于 PaddleOCR-VL 系列模型对图片和 PDF 进行版面解析、文字识别、公式识别、表格识别和印章识别,并在识别完成后对结果进行复核、编辑、复制和导出。
PaddleOCR-VL 在 X-AnyLabeling 中提供两种接入方式:
- 官方 API(推荐):直接调用 PaddleOCR 官方 API,适合快速验证模型效果、低成本体验和轻量开发场景,无需额外部署推理服务。
- 本地部署:通过 X-AnyLabeling-Server 自行部署推理服务,适合私有化部署、敏感数据处理和持续性标注任务。
1. 安装 X-AnyLabeling¶
推荐从官方 Release 下载对应平台的预编译包:
也可以通过 pip 安装:
启动后可以通过左侧工具栏中的 PaddleOCR 图标,或使用快捷键 Ctrl+4 打开 PaddleOCR 面板。
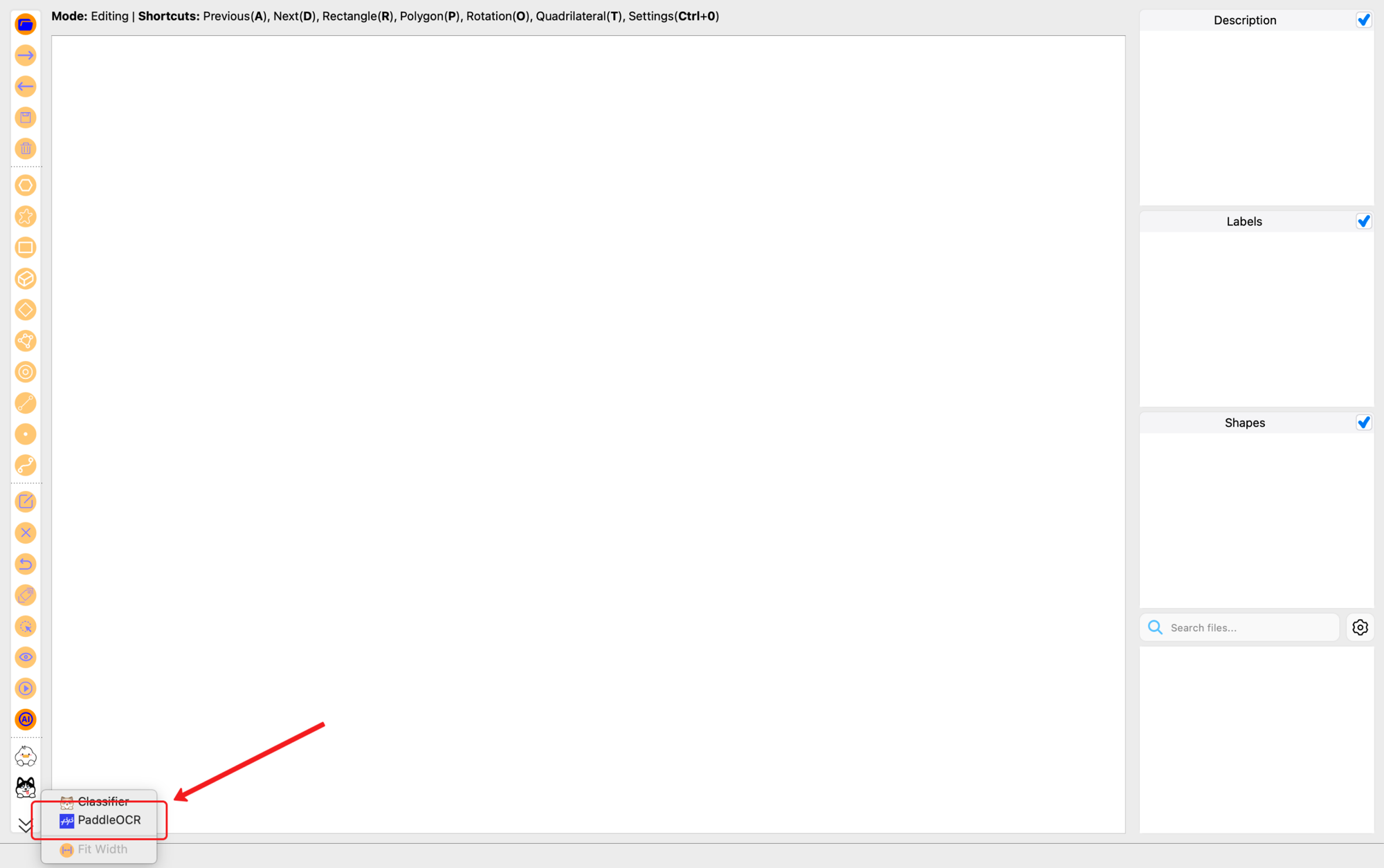
打开后即可看到 PaddleOCR 面板的初始界面:
2. 配置 PaddleOCR 官方 API¶
X-AnyLabeling 客户端默认支持 PaddleOCR 官方 API。首次打开 PaddleOCR 面板且尚未配置 API 信息时,界面会自动弹出 PPOCR API Settings 配置窗口;后续如需修改配置,也可以点击右侧结果面板顶部的齿轮按钮重新打开。
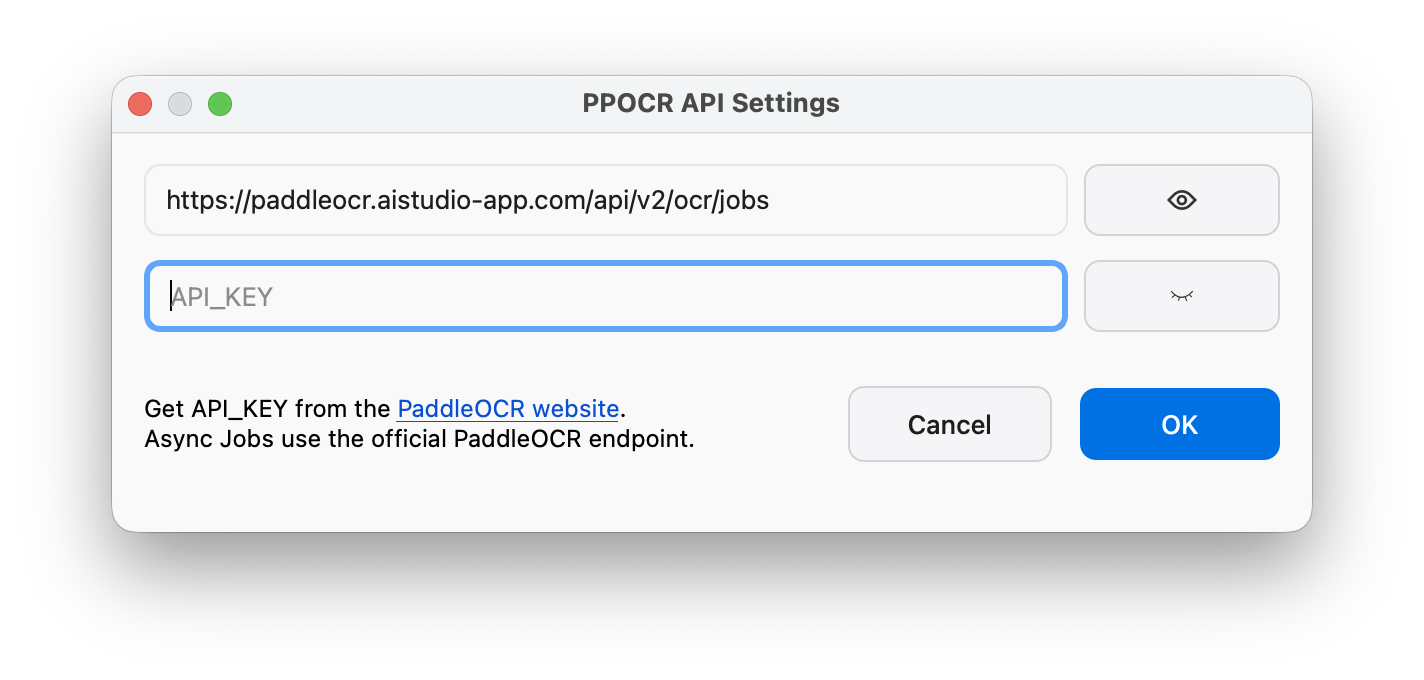
获取 API_KEY 的方式:
- 访问 PaddleOCR 官方网站:https://www.paddleocr.com
- 点击右上角 API,选择 PaddleOCR-VL-1.5。
- 打开示例代码,复制其中的
TOKEN(访问令牌)。 - 回到 X-AnyLabeling 的
PPOCR API Settings,将其粘贴到API_KEY字段并确认即可。
API_KEY 用于接口鉴权,支持申请每天免费解析数万文档页数。配置会保存在本地:
默认情况下,${workspace} 为用户主目录 ~;如果启动 X-AnyLabeling 时传入了 --work-dir,则以该目录为准。
右侧 Parsing Model 下拉框当前支持以下官方 API 选项:
PaddleOCR-VL-1.5 (API)PaddleOCR-VL (API)
3. 导入待解析文档¶
打开 PaddleOCR 面板后,点击左侧面板顶部的 + New Parsing 导入文件。导入后文件会自动复制到本地 PaddleOCR 工作目录,并自动加入解析队列。
当前 PaddleOCR 面板支持的文件类型:
| 类型 | 后缀 |
|---|---|
| PDF 文档 | .pdf |
| 图片 | .bmp, .cif, .gif, .jpeg, .jpg, .png, .tif, .tiff, .webp |
适用的真实场景包括教材页面、论文截图、票据图片、合同扫描件、表格文档、政企材料等。
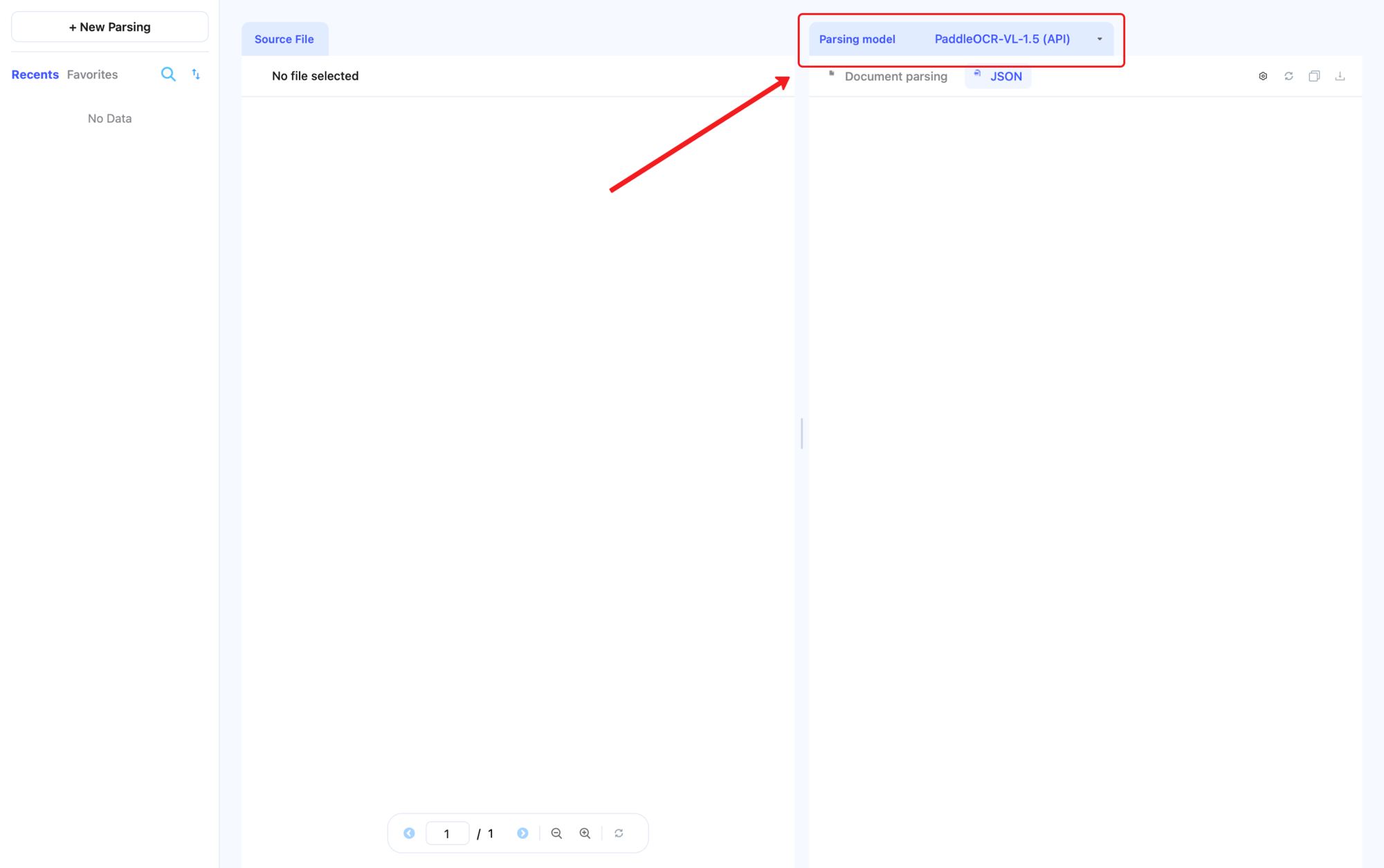
4. 选择解析模型¶
在右侧 Parsing Model 下拉框中可在 PaddleOCR-VL 系列的不同版本之间切换:
PaddleOCR-VL-1.5 (API)(推荐):在 OmniDocBench v1.5 上达到 94.5% 精度,支持异形框定位,对扫描、倾斜、弯折、屏幕拍摄及复杂光照等场景具备更强鲁棒性,并新增印章识别与文本检测识别能力。PaddleOCR-VL (API):初代版本。
5. 执行 Document Parsing¶
选择模型后,X-AnyLabeling 会自动开始解析。模型会对文档中的文本、公式、表格、图表、印章等内容进行识别和结构化处理。
左侧文件项左下角的彩色点表示解析状态:
- 蓝色:待解析或正在解析
- 绿色:解析完成
- 红色:解析失败
6. 对照原文档复核解析结果¶
解析完成后,X-AnyLabeling 会呈现左右对照视图:左侧为原始文档,右侧为模型的解析结果。开发者可以逐段检查文字内容、公式表达、表格结构、图表信息和印章结果是否准确,并通过以下操作进行复核:

- 单击左侧预览区或右侧结果区中的任意块,可以在两侧快速匹配并高亮对应内容。
- 双击右侧识别结果中的某个块,或点击该块的
纠正按钮,进入编辑状态。 - 鼠标悬停在源文件预览区的块上时,可以直接点击浮出的
复制按钮复制该块内容。 - 对识别结果做人工修正后,JSON 中会记录已编辑块;如需重新获取模型结果,可使用右侧重解析按钮。
针对不同类型的内容,X-AnyLabeling 提供专用编辑器:
| 编辑器 | 适用场景 |
|---|---|
| 富文本编辑器 | 普通文本、标题、页脚、印章等非表格/公式内容 |
| LaTeX 公式编辑器 | display_formula, formula, formula_number, algorithm,支持源码编辑与实时预览 |
| 表格编辑器 | table 或被识别为表格结构的内容,支持单元格编辑、增删行列等 |
7. 切换 JSON 视图查看结果¶
除了 Document Parsing 视图外,X-AnyLabeling 还支持 JSON 视图:
Document Parsing视图:以卡片形式展示版面块、文本、公式、表格、图片,适合人工阅读和结果复核。JSON视图:查看完整的结构化结果,适合开发者进行数据处理、训练样本构建、评测结果整理和业务系统集成。
8. 导出结果¶
完成复核和修正后,可以将标注结果导出,用于后续任务,典型用途包括:
- 构建 OCR 训练数据集
- 进行模型评测和误差分析
- 沉淀企业内部文档解析数据
- 接入业务系统进行自动化处理
在 Document Parsing 视图下,右侧工具栏的下载按钮会下载包含 Markdown 与相关资源的 ZIP;在 JSON 视图下则下载完整 JSON。
数据目录结构¶
X-AnyLabeling PaddleOCR 面板会将导入文件和解析结果保存在本地工作目录中:
${workspace}/xanylabeling_data/paddleocr/
├── api_settings.json
├── ui_state.json
├── files/
│ ├── example.pdf
│ ├── image.png
│ ├── __PDF_example/
│ │ ├── page_001.png
│ │ └── page_002.png
│ └── __BLOCK_IMAGES_image.png/
│ └── page_001_block_0001.png
└── jsons/
├── example.pdf.json
└── image.png.json
删除左侧文件项时,会同时删除源文件、本地 JSON、PDF 预览页和 block 裁剪图。
参考链接¶
- X-AnyLabeling 项目主页:https://github.com/CVHub520/X-AnyLabeling
- X-AnyLabeling PaddleOCR 面板文档:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/paddle_ocr.md
- X-AnyLabeling-Server(本地推理服务):https://github.com/CVHub520/X-AnyLabeling-Server
- PaddleOCR 官方网站:https://www.paddleocr.com
- PaddleOCR-VL 使用教程:PaddleOCR-VL 使用教程