1. PP-OCRv6 Introduction¶
PP-OCRv6 is the latest generation of the PP-OCR universal text recognition solution. Built on the newly designed PPLCNetV4 unified backbone, it offers tiny, small, and medium tiers targeting edge/IoT, mobile/desktop, and server scenarios respectively. PP-OCRv6 achieves a major breakthrough in language coverage—the medium/small tiers support 50 languages with a single unified model, including Simplified Chinese, Traditional Chinese, English, Japanese, and 46 Latin-script languages (tiny supports 49, excluding Japanese). On our in-house multi-scenario benchmark, PP-OCRv6_medium achieves +5.1% recognition accuracy and +4.6% detection Hmean over PP-OCRv5_server, with 2.37× GPU inference speedup; with only 34.5M parameters, it surpasses VLMs such as Qwen3-VL-235B and GPT-5.5 in accuracy.
Main contributions:
- Unified and Scalable Model Family: A three-tier OCR model family spanning 1.5M to 34.5M parameters. The medium tier achieves 86.2% detection Hmean and 83.2% recognition accuracy, serving as production-ready infrastructure for industrial deployment and large-scale data pipelines.
- Tailored Lightweight Architectural Innovations: (i) LCNetV4: a MetaFormer-style lightweight backbone with structural reparameterization; (ii) RepLKFPN: a detection neck with dilated reparameterizable depthwise convolutions for large receptive fields; (iii) EncoderWithLightSVTR: a recognition neck with local-global attention and additive skip connections.
- Extensive Multi-Language and Scenario Generalization: A single model scaled to support 50 languages and diverse challenging industrial scenes (e.g., digital displays, dot-matrix characters, tire prints), significantly improving OCR performance in scenarios traditionally underserved by general-purpose VLMs.
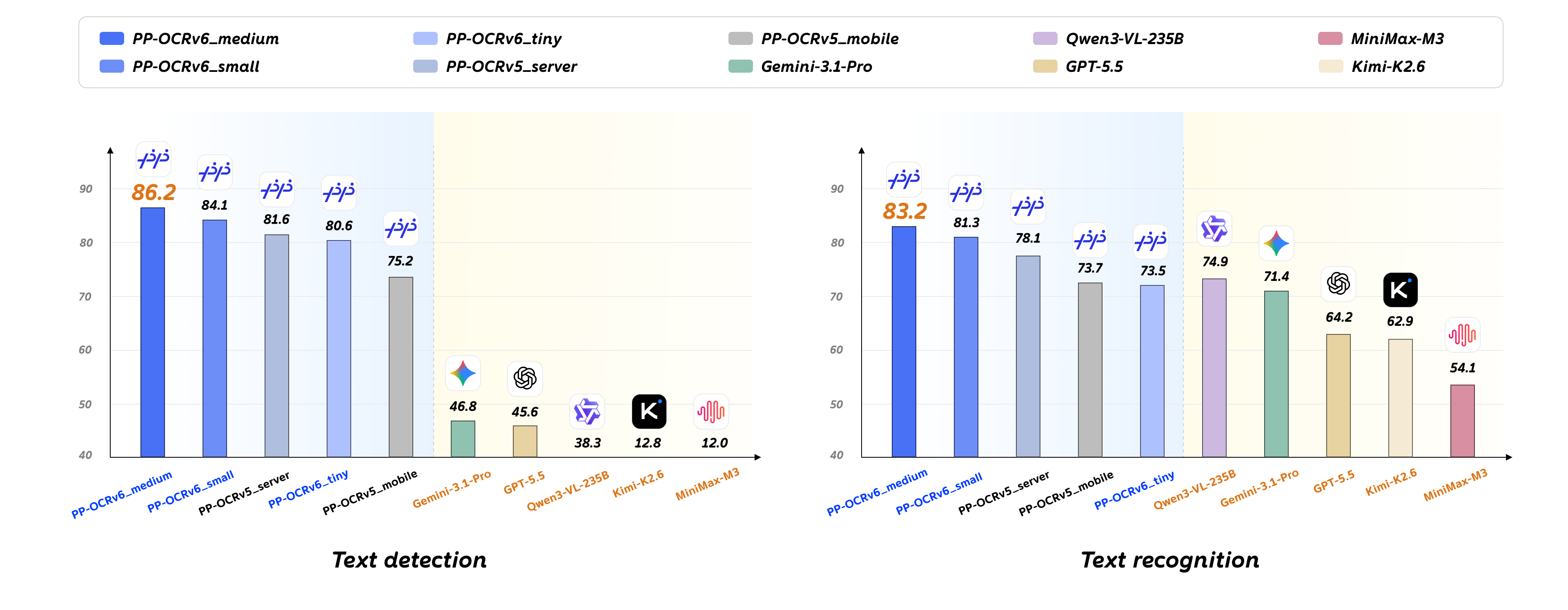
Performance comparison between PP-OCRv6, PP-OCRv5, and Vision-Language Models. Left: text detection average Hmean (%); Right: text recognition weighted average accuracy (%).
2. Key Technical Improvements¶
2.1 Unified Backbone: PPLCNetV4¶
LCNetV4Block: Following the MetaFormer paradigm, each layer is decomposed into a Token Mixer and a Channel Mixer. Given input feature \(\mathbf{x} \in \mathbb{R}^{C \times H \times W}\):
where \(\text{DW}(\cdot)\) is a 3×3 depthwise convolution (Token Mixer), SE is an optional channel attention module, \(W_1 \in \mathbb{R}^{2C \times C}\) and \(W_2 \in \mathbb{R}^{C \times 2C}\) form the Channel Mixer with expansion ratio 2, and \(\sigma\) is GELU activation.
Task-Adaptive Downsampling: The same backbone serves both tasks via different stride strategies—detection mode uses standard stride-2 spatial downsampling producing multi-scale feature maps (stride 4/8/16/32); recognition mode uses asymmetric stride \((2,1)\) at Stage 3/4, reducing height only while preserving width, followed by height-axis average pooling to produce 1-D sequential features for CTC/NRTR decoding.
Comparison with LCNetV3:
| Design Aspect | LCNetV3 | LCNetV4 |
|---|---|---|
| Architecture | MobileNet-style (DW→SE→PW) | MetaFormer (TokenMixer + ChannelMixer) |
| Channel Interaction | Single 1×1 PW Conv | Expand(2×)→Act→Compress + residual |
| Spatial Mixing | Plain DW Conv | RepDWConv (3×3 + 1×1 + identity) |
| BN Initialization | Standard | Zero-init on compress BN |
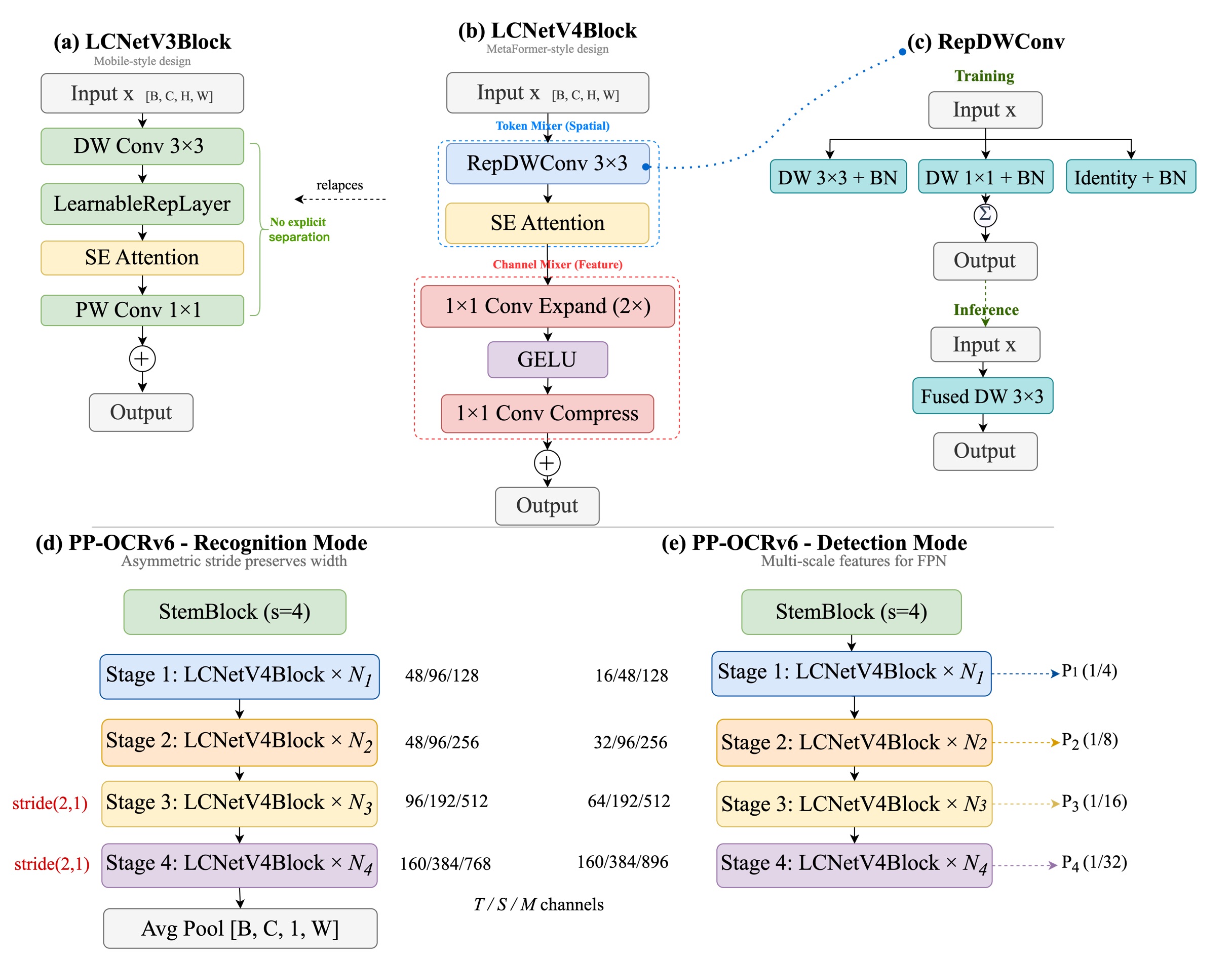
PPLCNetV4 backbone architecture.
2.2 Detection Module¶
- RepLKFPN: Lightweight large-kernel FPN using DilatedReparamBlock (7×7 depthwise conv + dilated branches), 31% fewer parameters than PP-OCRv5's RSEFPN (118K vs 172K) with receptive field expanded from 3×3 to 7×7.
- Auxiliary Deep Supervision: Prediction heads at P2, P3, P4 levels for stronger gradient signals during training.
- DiceBCE Loss: Combined DiceLoss + Focal Loss for better per-pixel supervision on small and dense text.
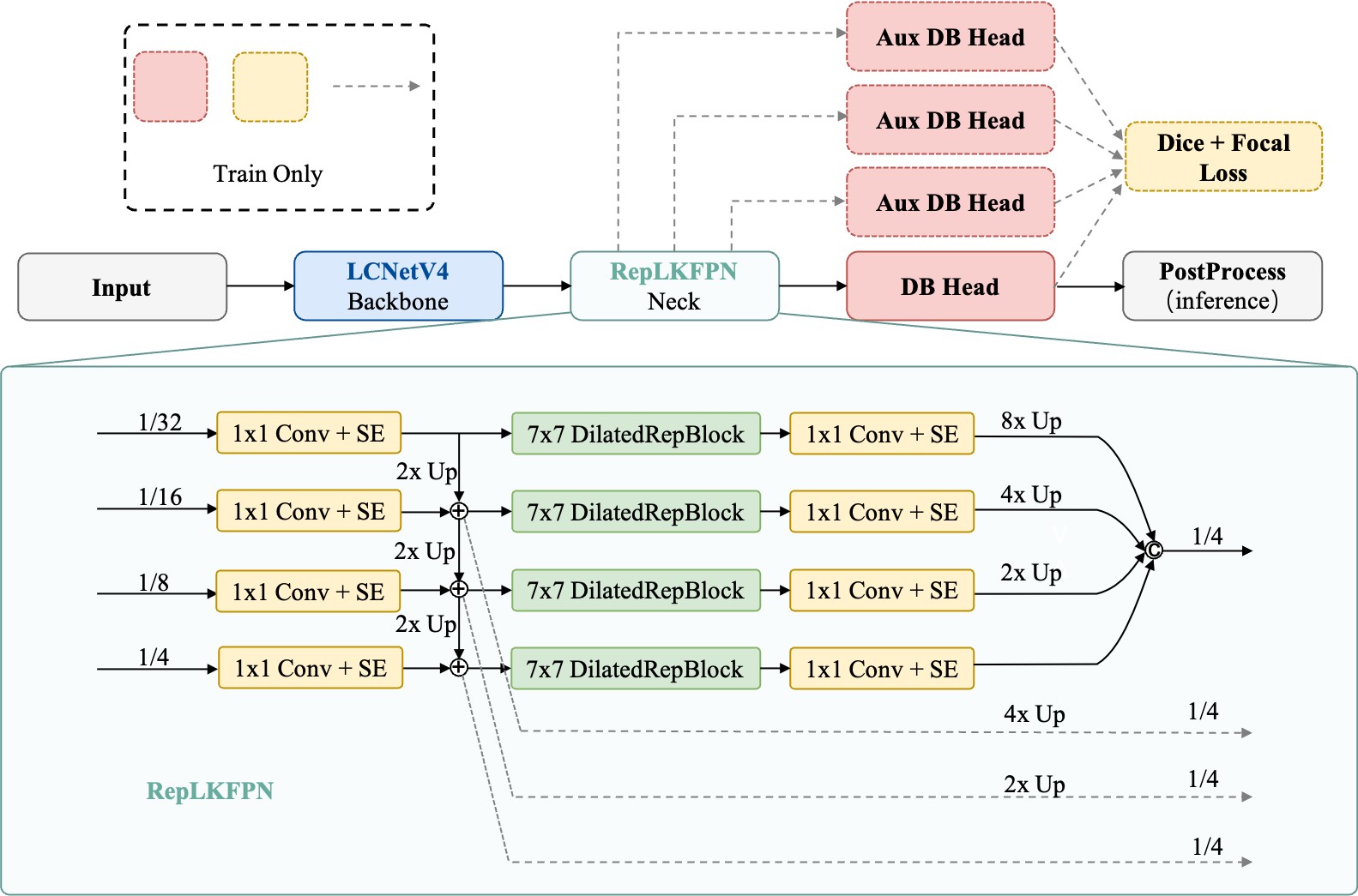
PP-OCRv6 detection module architecture.
2.3 Recognition Module¶
- EncoderWithLightSVTR Neck: Local context modeling (1×7 depthwise conv) + global self-attention (1-2 Transformer layers), with additive skip connections (instead of concatenation in PP-OCRv5) to reduce parameters.
- Multi-Head Decoder: CTCHead for efficient parallel inference; NRTRHead for auxiliary training supervision (removed at inference).
- Tiny Model Design: No neck (direct reshape + FC), trained with knowledge distillation from the medium model.
- Multilingual Unification: Dictionary extended with ~200 diacritical characters, enabling single-model 50-language coverage.
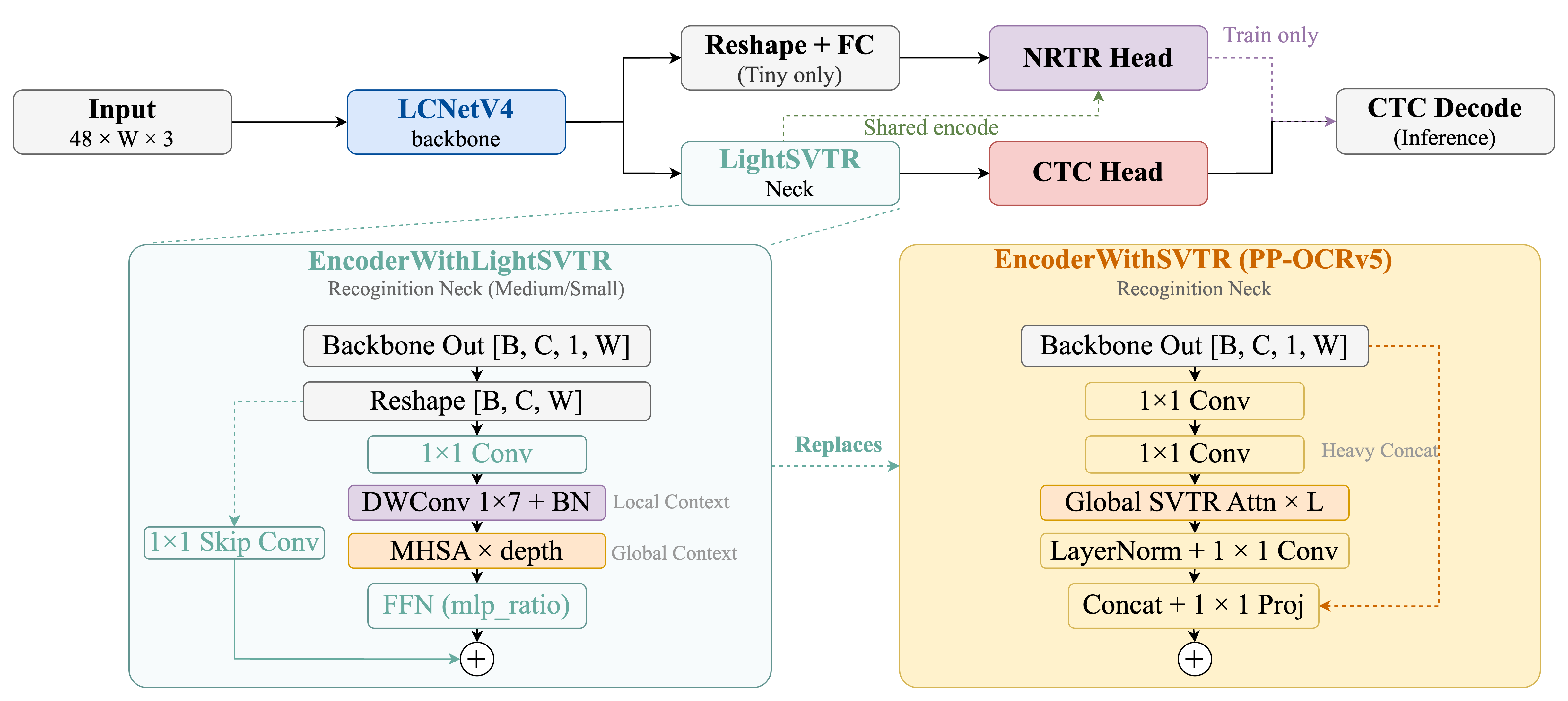
PP-OCRv6 recognition module architecture.
3. Key Metrics¶
3.1 Text Detection¶
Text detection Hmean (%) on our in-house multi-scenario benchmark (16 categories):
| Model | AVG | HW-CN | HW-EN | Print-CN | Print-EN | TC | Anc. | JP | Blur | Emo. | Warp | Pin. | Art. | Tab. | Rot. | Indus. | Gen. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv6_medium | 86.2 | 83.7 | 84.0 | 95.1 | 93.7 | 86.3 | 80.2 | 84.3 | 94.1 | 99.6 | 88.6 | 74.0 | 69.0 | 96.8 | 93.8 | 73.3 | 82.8 |
| PP-OCRv6_small | 84.1 | 80.5 | 87.1 | 94.2 | 93.6 | 85.7 | 72.6 | 82.3 | 92.6 | 99.7 | 87.6 | 69.6 | 65.3 | 95.6 | 93.7 | 67.6 | 78.2 |
| PP-OCRv6_tiny | 80.6 | 79.4 | 85.9 | 93.1 | 92.3 | 83.7 | 63.0 | 76.6 | 89.3 | 99.8 | 86.1 | 59.0 | 60.1 | 94.7 | 91.0 | 62.0 | 73.8 |
| PP-OCRv5_server | 81.6 | 80.3 | 84.1 | 94.5 | 91.7 | 81.5 | 67.6 | 77.2 | 90.1 | 96.2 | 87.6 | 67.1 | 67.3 | 97.1 | 80.0 | 64.3 | 79.7 |
| PP-OCRv5_mobile | 75.2 | 74.4 | 77.7 | 90.5 | 91.0 | 82.3 | 58.1 | 72.7 | 87.4 | 93.6 | 82.7 | 57.5 | 52.5 | 92.8 | 64.7 | 52.8 | 72.1 |
| Gemini-3.1-Pro | 46.8 | 53.4 | 56.5 | 47.3 | 47.6 | 39.0 | 45.8 | 38.2 | 50.0 | 68.1 | 44.6 | 40.6 | 65.2 | 26.9 | 22.1 | 52.5 | 50.2 |
| GPT-5.5 | 45.6 | 42.4 | 58.5 | 50.2 | 51.9 | 35.0 | 26.7 | 42.0 | 49.1 | 97.5 | 37.7 | 36.3 | 52.0 | 71.0 | 10.0 | 36.2 | 32.6 |
| Qwen3-VL-235B | 38.3 | 56.5 | 66.0 | 41.7 | 37.0 | 19.3 | 13.1 | 27.0 | 38.5 | 81.2 | 28.5 | 33.0 | 68.3 | 19.6 | 2.1 | 48.4 | 32.3 |
3.2 Text Recognition¶
Text recognition accuracy (%) on our in-house multi-scenario benchmark (15 categories):
| Model | W-Avg | HW-CN | HW-EN | Print-CN | Print-EN | TC | Anc. | JP | Conf. | Spec. | Gen. | Pin. | Art. | Indus. | Screen | Card |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv6_medium | 83.2 | 62.1 | 67.8 | 91.5 | 94.1 | 78.6 | 72.4 | 90.5 | 64.9 | 61.7 | 87.5 | 78.1 | 71.2 | 77.4 | 82.5 | 88.1 |
| PP-OCRv6_small | 81.3 | 57.6 | 61.1 | 90.5 | 93.3 | 77.0 | 71.1 | 88.2 | 64.1 | 60.2 | 85.7 | 75.9 | 68.4 | 76.4 | 79.7 | 86.9 |
| PP-OCRv6_tiny | 73.5 | 40.1 | 39.3 | 86.7 | 88.4 | 65.0 | 68.4 | 89.8 | 52.3 | 57.1 | 78.0 | 65.4 | 54.7 | 62.1 | 71.2 | 80.5 |
| PP-OCRv5_server | 78.1 | 58.0 | 59.6 | 90.1 | 85.1 | 74.7 | 60.4 | 73.7 | 59.4 | 56.8 | 86.5 | 74.4 | 64.0 | 70.2 | 68.1 | 87.6 |
| PP-OCRv5_mobile | 73.7 | 41.7 | 50.9 | 86.0 | 86.0 | 72.0 | 57.8 | 75.8 | 55.7 | 54.8 | 80.7 | 72.5 | 54.0 | 59.3 | 57.6 | 81.7 |
| Qwen3-VL-235B | 74.9 | 49.7 | 73.2 | 82.3 | 86.2 | 76.4 | 33.6 | 66.2 | 56.1 | 49.0 | 82.5 | 76.5 | 69.6 | 74.7 | 73.8 | 78.7 |
| Gemini-3.1-Pro | 71.4 | 46.4 | 73.0 | 80.0 | 90.5 | 69.5 | 18.0 | 67.2 | 54.4 | 50.3 | 74.6 | 75.9 | 63.1 | 69.1 | 73.2 | 75.9 |
| GPT-5.5 | 64.2 | 19.2 | 56.9 | 75.7 | 82.2 | 57.5 | 63.7 | 58.6 | 49.1 | 48.3 | 67.7 | 50.4 | 53.0 | 62.4 | 67.7 | 71.1 |
3.3 End-to-End Inference Speed (s/image)¶
Tested on 200 images (general + document scenes), including image I/O, pre/post-processing, and model inference.
| Hardware | Backend | PP-OCRv6_medium | PP-OCRv6_small | PP-OCRv6_tiny | PP-OCRv5_server | PP-OCRv5_mobile | PP-OCRv4_mobile |
|---|---|---|---|---|---|---|---|
| NVIDIA A100 | PaddlePaddle | 0.29 | 0.25 | 0.13 | 0.32 | 0.25 | 0.14 |
| NVIDIA A100 | TensorRT | -- | 0.32 | 0.16 | -- | 0.33 | 0.16 |
| NVIDIA V100 | PaddlePaddle | 0.72 | 0.49 | 0.21 | 0.66 | 0.50 | 0.25 |
| NVIDIA V100 | ONNX Runtime | 0.67 | 0.53 | 0.29 | 0.77 | 0.46 | 0.27 |
| NVIDIA V100 | TensorRT | 0.77 | 0.60 | 0.23 | 0.73 | 0.59 | 0.27 |
| Intel Xeon 8350C | PaddlePaddle | 2.05 | 0.79 | 0.32 | 2.04 | 0.80 | 0.62 |
| Intel Xeon 8350C | OpenVINO | 1.40 | 0.59 | 0.20 | 7.30 | 0.78 | 0.60 |
| Intel Xeon 8350C | ONNX Runtime | 3.31 | 0.61 | 0.22 | 6.36 | 0.61 | 0.49 |
| Apple M4 | PaddlePaddle | 8.82 | 3.07 | 0.96 | >10 | 5.82 | 5.65 |
| Apple M4 | ONNX Runtime | 5.55 | 1.29 | 0.35 | 7.20 | 1.10 | 1.02 |
- PP-OCRv6_medium matches or outperforms PP-OCRv5_server on all platforms: 1.1× faster on A100 (0.29s vs 0.32s), 1.15× on V100 ONNX Runtime (0.67s vs 0.77s), 5.2× on Intel Xeon OpenVINO (1.40s vs 7.30s).
- PP-OCRv6_small matches PP-OCRv5_mobile in latency on most platforms with higher accuracy; 1.9× faster on Apple M4 PaddlePaddle (3.07s vs 5.82s).
- PP-OCRv6_tiny is the fastest model across all platforms: 6.1× over PP-OCRv5_mobile on Apple M4 PaddlePaddle (0.96s vs 5.82s), 3.9× on Intel Xeon OpenVINO (0.20s vs 0.78s), reaching 0.13s on A100.
4. Visualization¶
4.1 Detection Comparison¶

Text detection comparison. Left to right: PP-OCRv6_medium, PP-OCRv5_server, Gemini-3.1-Pro, GPT-5.5.
4.2 Hallucination Comparison¶

PP-OCRv6_medium vs VLMs hallucination comparison. PP-OCRv6 faithfully reproduces visual text content, while VLMs introduce hallucinated corrections based on linguistic priors.
4.3 End-to-End OCR Comparison¶
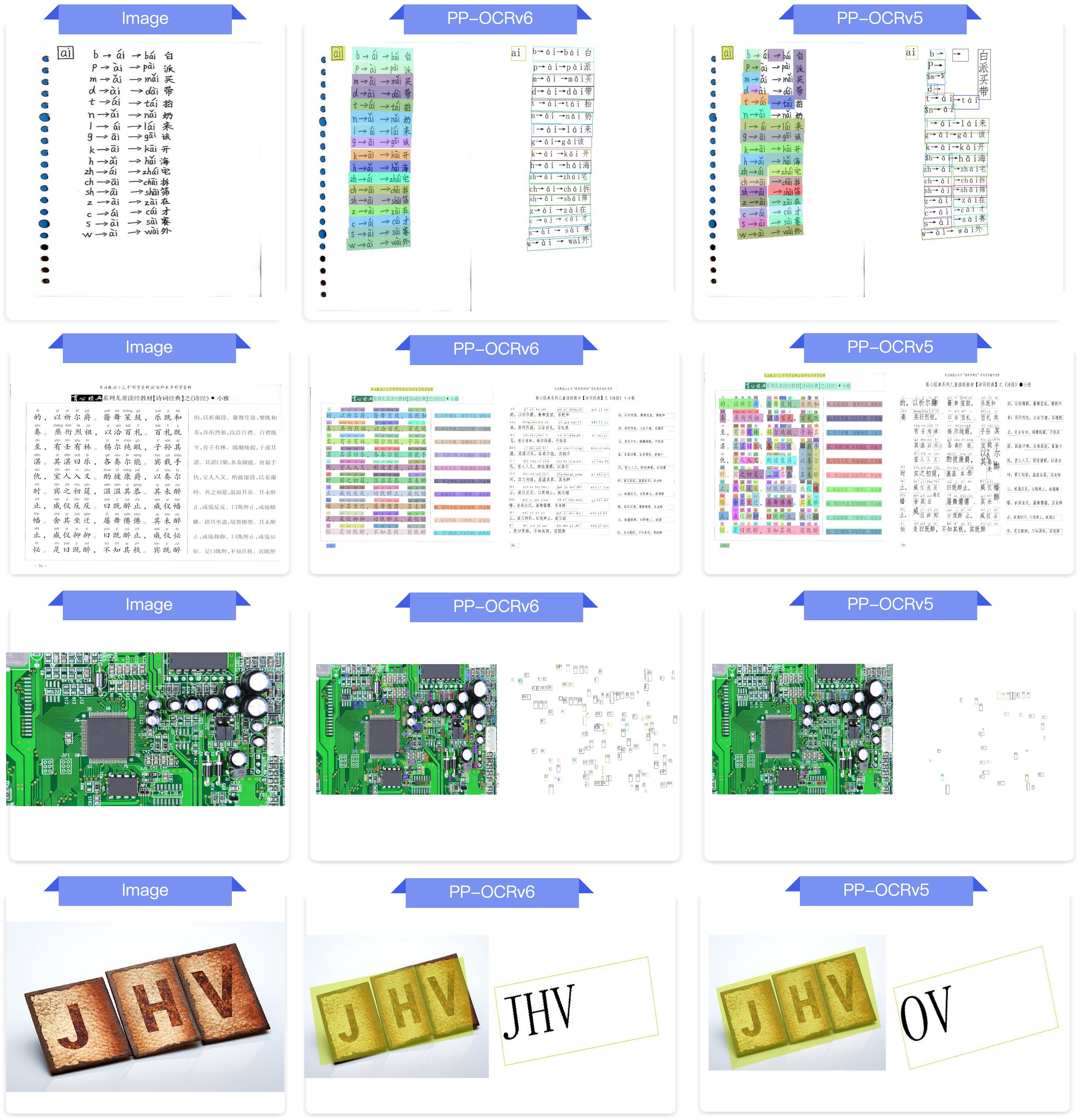
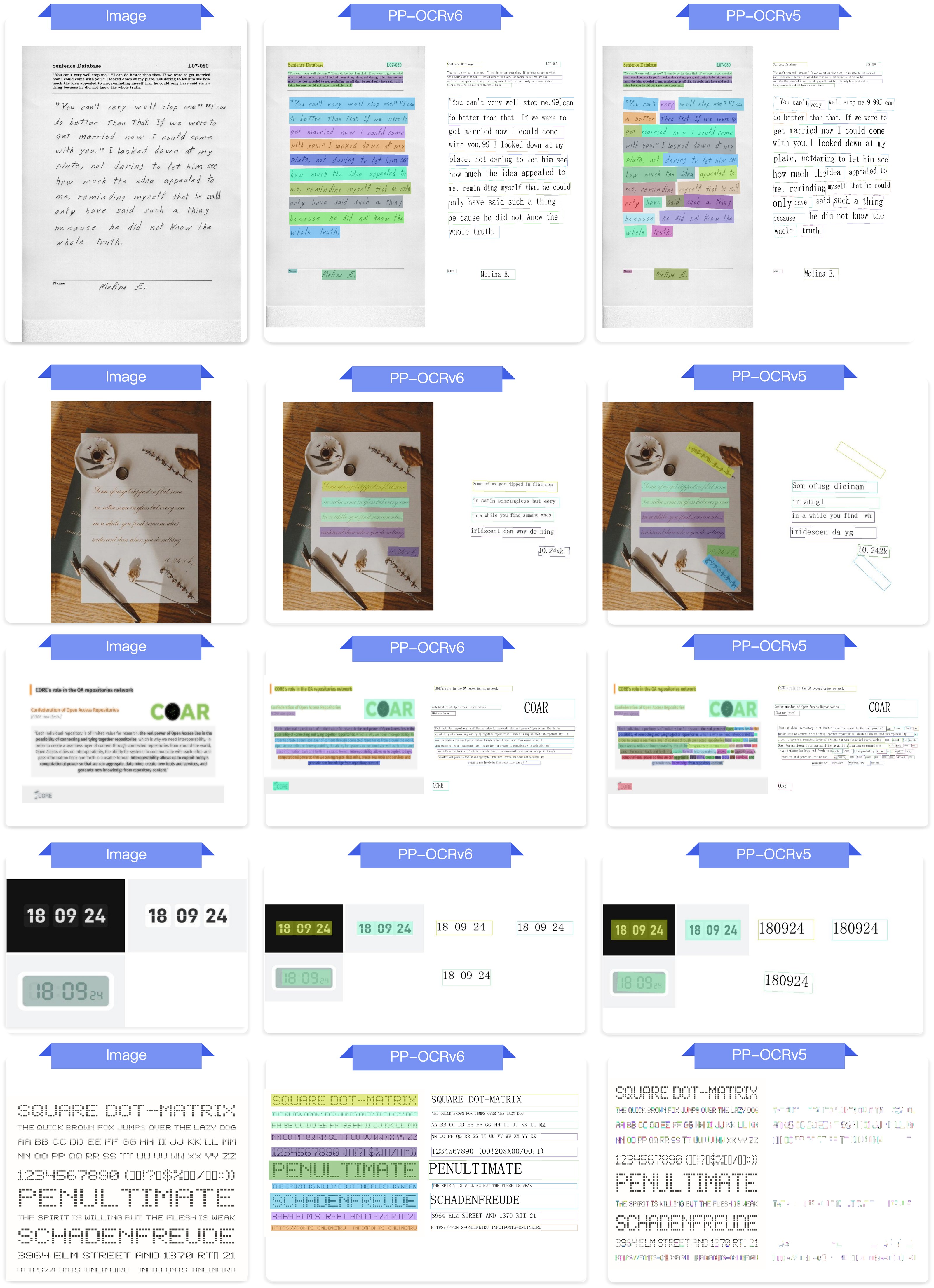
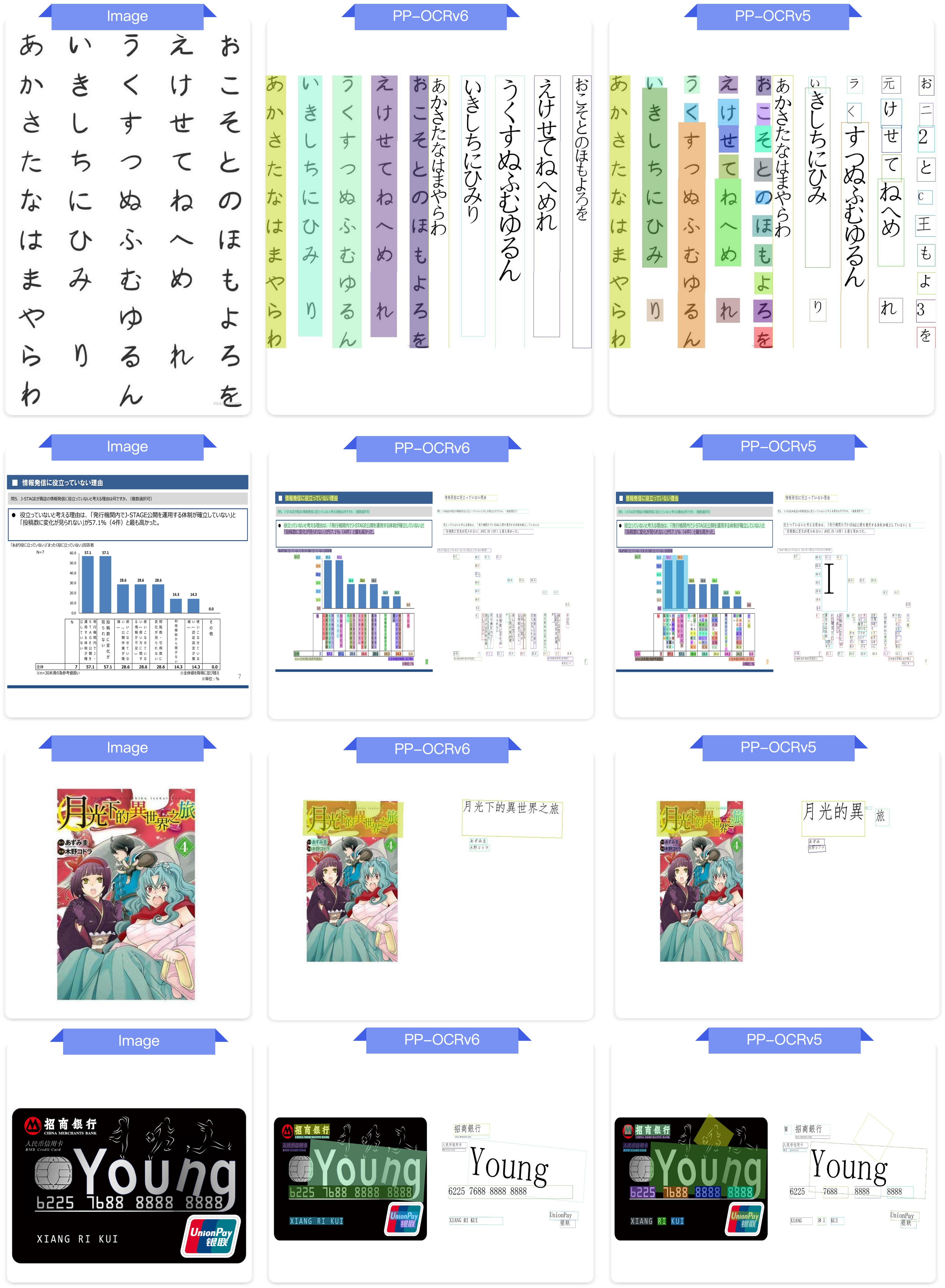
End-to-end OCR comparison between PP-OCRv6_medium and PP-OCRv5_server across Chinese, English, Japanese, artistic fonts, industrial characters, rotated text, pinyin, and dot-matrix characters.
5. Quick Start¶
from paddleocr import PaddleOCR
# Default: PP-OCRv6_medium
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
result = ocr.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
# CLI usage
paddleocr ocr -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False
Using Transformers Engine:
PP-OCRv6 supports inference via Hugging Face Transformers (requires transformers>=5.8.0):
from paddleocr import TextRecognition
model = TextRecognition(
model_name="PP-OCRv6_medium_rec",
engine="transformers",
)
output = model.predict(input="general_ocr_rec_001.png", batch_size=1)
for res in output:
res.print()
Using High-Performance Inference (ONNX Runtime backend):
Enable the high-performance inference plugin with enable_hpi=True:
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
enable_hpi=True,
)
result = ocr.predict("general_ocr_002.png")
The HPI plugin requires additional installation. See High-Performance Inference Guide.
6. Deployment and Custom Development¶
- Multi-OS Support: Compatible with Windows, Linux, and Mac.
- Multi-Hardware Support: Supports NVIDIA GPU, Intel CPU, Kunlun, Ascend, and more.
- High-Performance Inference Plugin: See High-Performance Inference Guide.
- Serving Deployment: See Serving Deployment Guide.
- Custom Development: Supports custom dataset training, dictionary extension, and model fine-tuning. See Text Detection Tutorial and Text Recognition Tutorial.