PaddleOCR-VL Introduction
1. PaddleOCR-VL Introduction¶
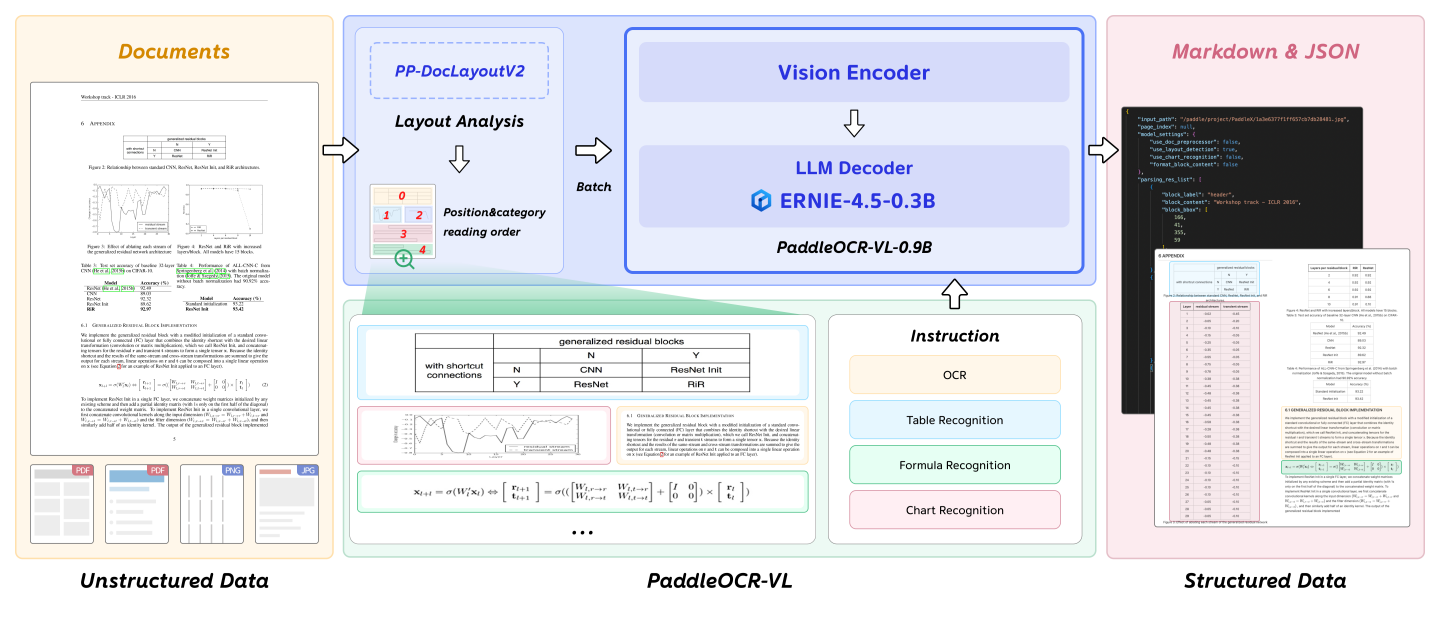
PaddleOCR-VL is a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
Key Metrics:¶
Core Features¶
-
Compact yet Powerful VLM Architecture: We present a novel vision-language model that is specifically designed for resource-efficient inference, achieving outstanding performance in element recognition. By integrating a NaViT-style dynamic high-resolution visual encoder with the lightweight ERNIE-4.5-0.3B language model, we significantly enhance the model’s recognition capabilities and decoding efficiency. This integration maintains high accuracy while reducing computational demands, making it well-suited for efficient and practical document processing applications.
-
SOTA Performance on Document Parsing: PaddleOCR-VL achieves state-of-the-art performance in both page-level document parsing and element-level recognition. It significantly outperforms existing pipeline-based solutions and exhibiting strong competitiveness against leading vision-language models (VLMs) in document parsing. Moreover, it excels in recognizing complex document elements, such as text, tables, formulas, and charts, making it suitable for a wide range of challenging content types, including handwritten text and historical documents. This makes it highly versatile and suitable for a wide range of document types and scenarios.
-
Multilingual Support: PaddleOCR-VL Supports 109 languages, covering major global languages, including but not limited to Chinese, English, Japanese, Latin, and Korean, as well as languages with different scripts and structures, such as Russian (Cyrillic script), Arabic, Hindi (Devanagari script), and Thai. This broad language coverage substantially enhances the applicability of our system to multilingual and globalized document processing scenarios.
2. Model Architecture¶
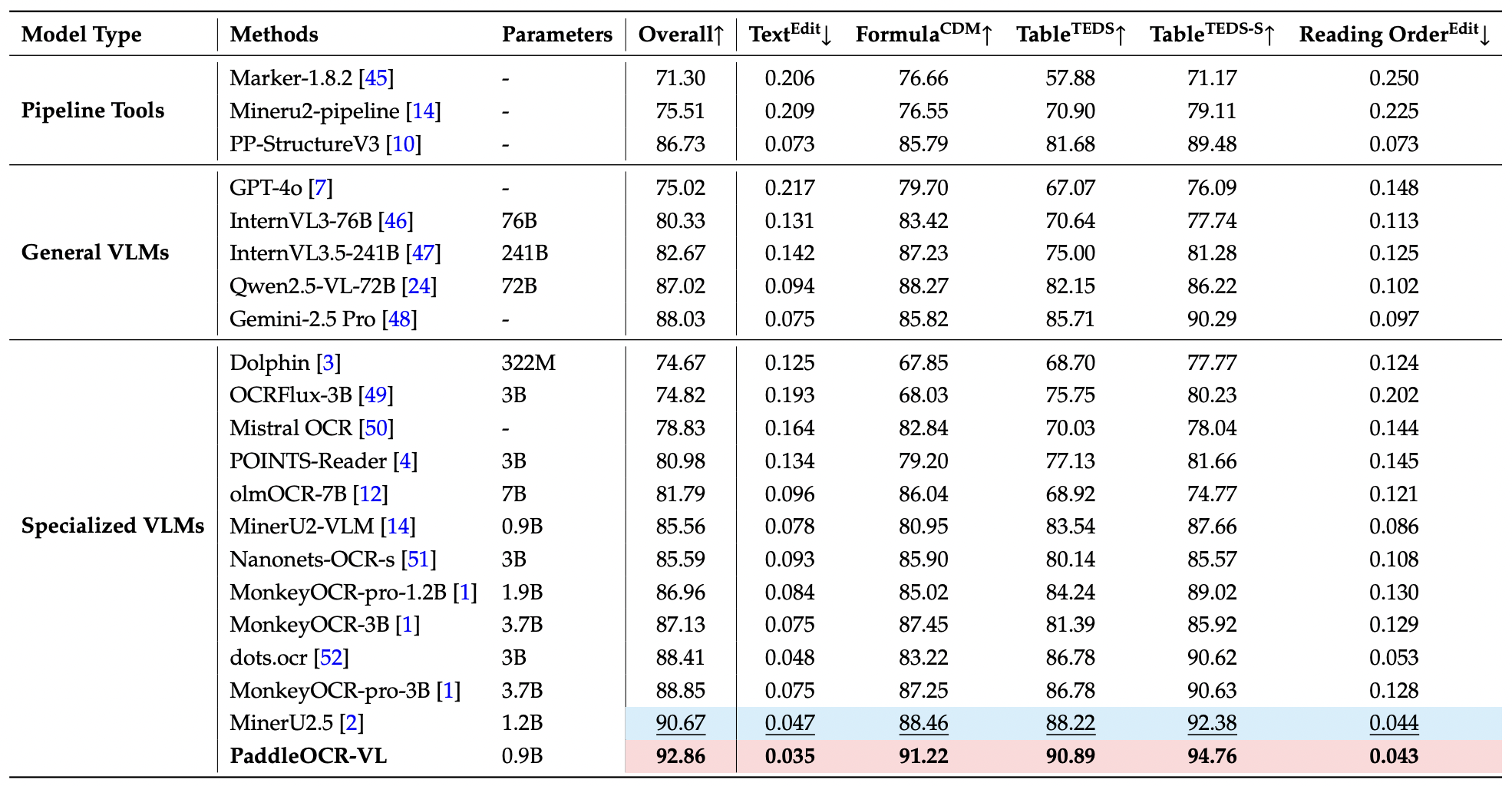
3. Model Performance¶
Page-Level Document Parsing¶
OmniDocBench v1.5¶
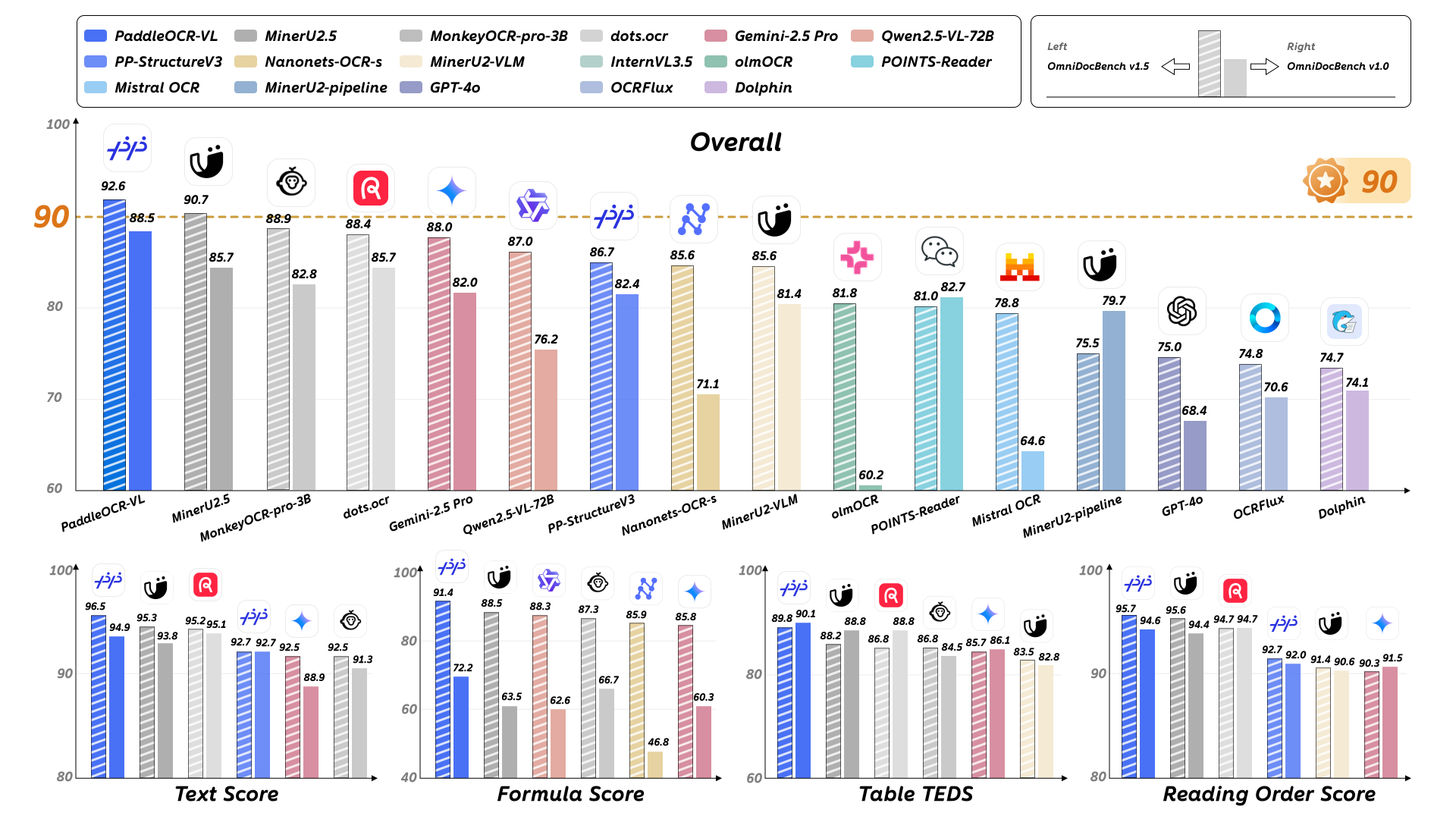
PaddleOCR-VL achieves SOTA performance for overall, text, formula, tables and reading order on OmniDocBench v1.5.¶
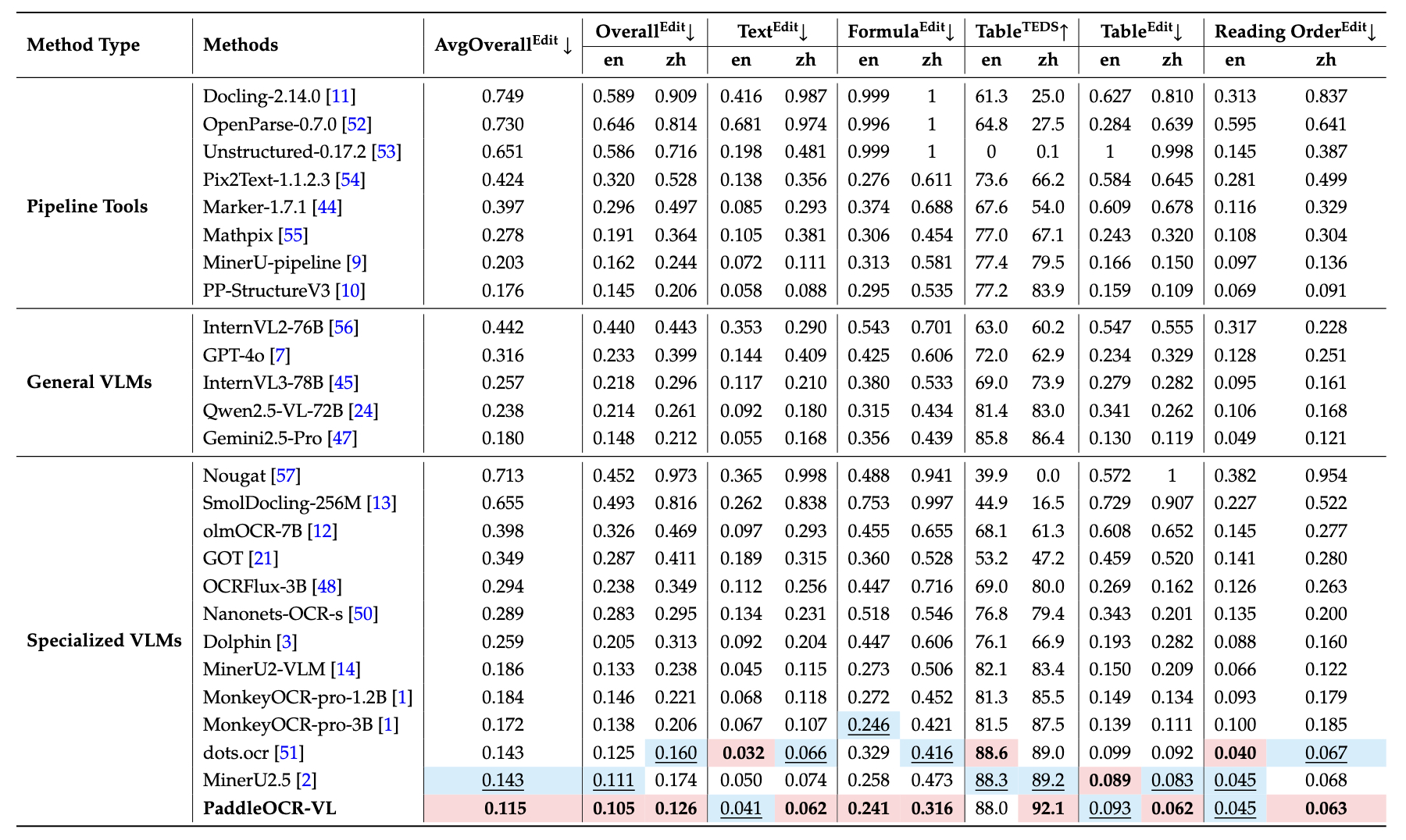
OmniDocBench v1.0¶
PaddleOCR-VL achieves SOTA performance for almost all metrics of overall, text, formula, tables and reading order on OmniDocBench v1.0.¶
Element-level Recognition¶
Text¶
Comparison of OmniDocBench-OCR-block Performance
PaddleOCR-VL’s robust and versatile capability in handling diverse document types, establishing it as the leading method in the OmniDocBench-OCR-block performance evaluation.

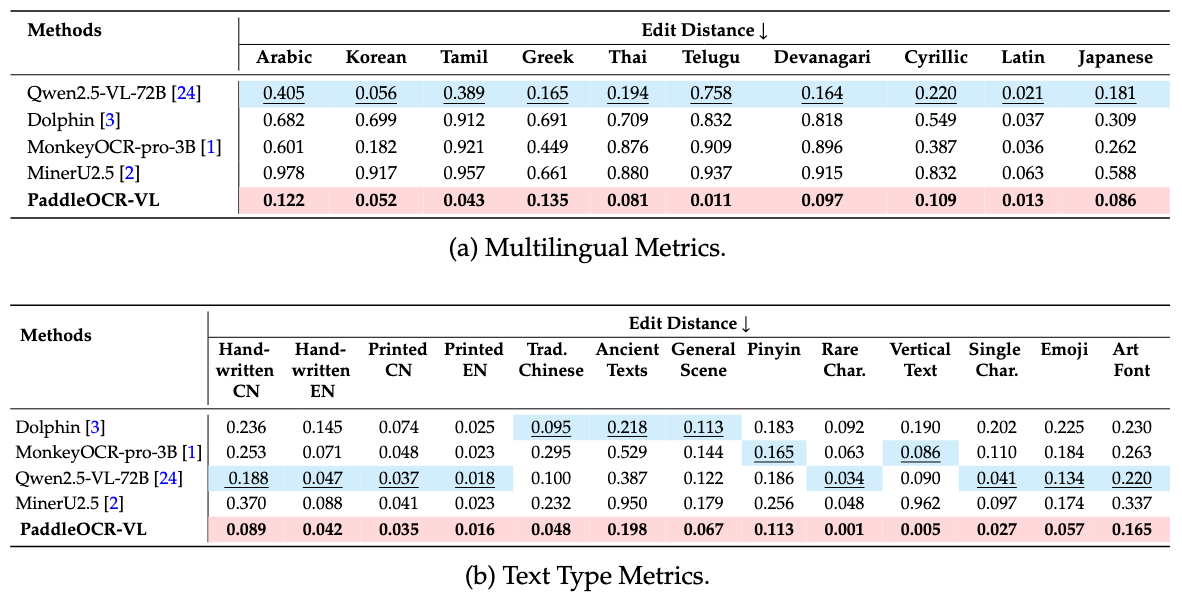
Comparison of In-house-OCR-block Performance
In-house-OCR provides a evaluation of performance across multiple languages and text types. Our model demonstrates outstanding accuracy with the lowest edit distances in all evaluated scripts.
Table¶
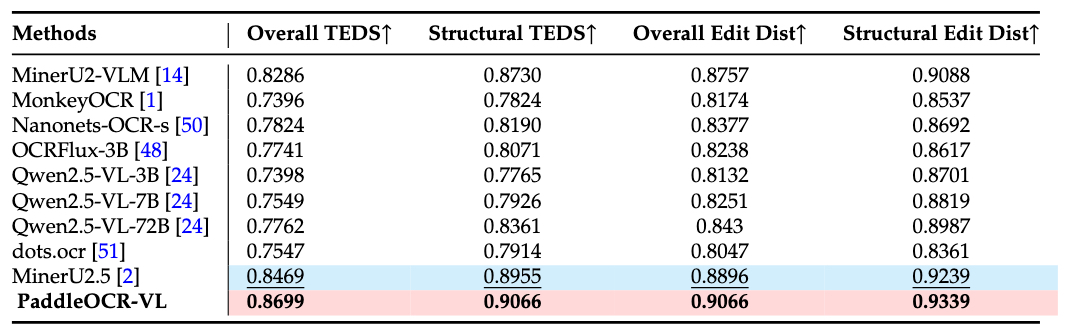
Comparison of In-house-Table Performance
Our self-built evaluation set contains diverse types of table images, such as Chinese, English, mixed Chinese-English, and tables with various characteristics like full, partial, or no borders, book/manual formats, lists, academic papers, merged cells, as well as low-quality, watermarked, etc. PaddleOCR-VL achieves remarkable performance across all categories.
Formula¶
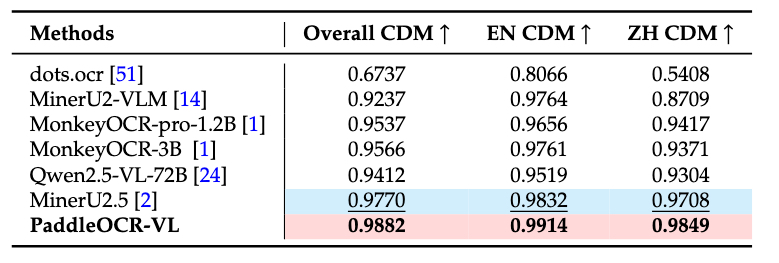
Comparison of In-house-Formula Performance
In-house-Formula evaluation set contains simple prints, complex prints, camera scans, and handwritten formulas. PaddleOCR-VL demonstrates the best performance in every category.
Chart¶
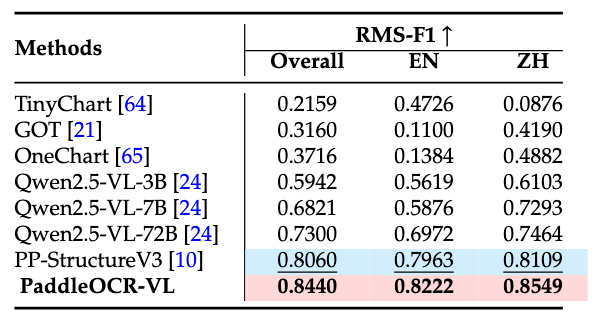
Comparison of In-house-Chart Performance
The evaluation set is broadly categorized into 11 chart categories, including bar-line hybrid, pie, 100% stacked bar, area, bar, bubble, histogram, line, scatterplot, stacked area, and stacked bar. PaddleOCR-VL not only outperforms expert OCR VLMs but also surpasses some 72B-level multimodal language models.
4、Inference and deployment Performance¶
To improve the inference performance of PaddleOCR-VL, we introduce multi-threading asynchronous execution into the inference workflow. The process is divided into three main stages—data loading (e.g., rendering PDF pages as images), layout model processing, and VLM inference—each running in a separate thread. Data is transferred between adjacent stages via queues, enabling concurrent execution for higher efficiency. We measured the end-to-end inference speed and GPU usage on the OmniDocBench v1.0 dataset, processing PDF files in batches of 512 on a single NVIDIA A100 GPU.
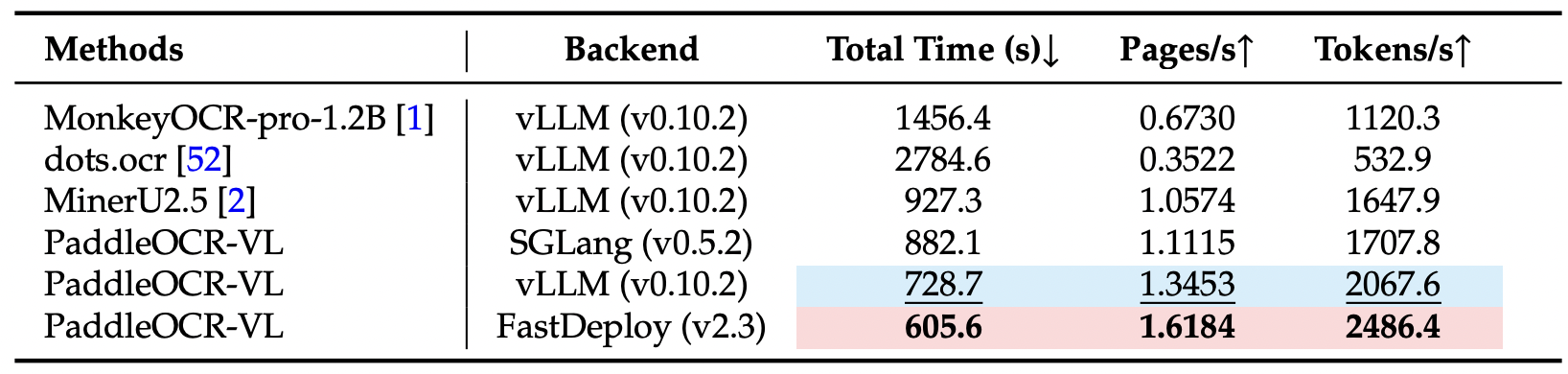
Notes: † means vLLM backend,‡ means sglang backend.
5. Visualization¶
Comprehensive Document Parsing¶




Text Recognition¶


Table Recognition¶
Formula Recognition¶

Chart Recognition¶

6. FAQ¶
1.How to use PaddleOCR-VL for document parsing?
Please refer to our usage documentation PaddleOCR-VL Usage.
2. How to fine-tune the PaddleOCR-VL model?
Currently, we do not support fine-tuning of the model, but it is a high-priority feature and will be released soon. Please stay tuned.
3. Why was my chart not recognized and how can I use chart recognition?
Because our default chart recognition function is turned off, it needs to be manually turned on. Please refer to PaddleOCR-VL Usage and set the use_chart_recognition为True parameters to True turn it on.
4. What are the 109 supported languages?
Chinese, English, Korea, Japanese, Thai, Greek, Tamil, Telugu
Arabic: Arabic, Persian, Uyghur, Urdu, Pashto, Kurdish, Sindhi, Balochi
Latin: French, German, Afrikaans, Italian, Spanish, Bosnian, Portuguese, Czech, Welsh, Danish, Estonian, Irish, Croatian, Uzbek, Hungarian, Serbian (Latin), Indonesian, Occitan, Icelandic, Lithuanian, Maori, Malay, Dutch, Norwegian, Polish, Slovak, Slovenian, Albanian, Swedish, Swahili, Tagalog, Turkish, Latin, Azerbaijani, Kurdish, Latvian, Maltese, Pali, Romanian, Vietnamese, Finnish, Basque, Galician, Luxembourgish, Romansh, Catalan, Quechua
Cyrillic: Russian, Belarusian, Ukrainian, Serbian (Cyrillic), Bulgarian, Mongolian, Abkhazian, Adyghe, Kabardian, Avar, Dargin, Ingush, Chechen, Lak, Lezgin, Tabasaran, Kazakh, Kyrgyz, Tajik, Macedonian, Tatar, Chuvash, Bashkir, Malian, Moldovan, Udmurt, Komi, Ossetian, Buryat, Kalmyk, Tuvan, Sakha, Karakalpak
Devanagari: Hindi, Marathi, Nepali, Bihari, Maithili, Angika, Bhojpuri, Magahi, Santali, Newari, Konkani, Sanskrit, Haryanvi
5. If the results of the layout check are not satisfactory, what solutions can be optimized?
Since layout detection is mainly trained for various document scenarios, if your test data is non-standard documents such as license plates, tickets images or ID Cards and you want to do OCR recognition, you can directly use the PaddleOCR-VL-0.9B model and turn off the layout detection model by setting use_layout_detection to False. If you find any layout detection errors, you can directly try the effect of using PaddleOCR-VL-0.9B alone. We recommend using the ERNIEKit toolkit to perform Supervised Fine-Tuning (SFT) on the PaddleOCR-VL-0.9B model. For detailed steps, please refer to the ERNIEKit documentation.