PaddleOCR-VL-1.6简介
1. PaddleOCR-VL-1.6 简介¶
PaddleOCR-VL-1.6 在 PaddleOCR-VL-1.5 的基础上进一步优化,通过系统分析当前模型中的欠优化区域,进行针对性数据优化,并采用精细化的后训练策略,在文档解析基准 OmniDocBench v1.6 上取得 96.33% 的最新 SOTA(最佳)结果。同时,PaddleOCR-VL-1.6 在面向真实世界物理畸变鲁棒性的 Real5-OmniDocBench 基准测试中,也在各个场景下均达到 SOTA 性能。此外,在印章识别、文字检测识别和图表识别三个子任务上,PaddleOCR-VL-1.6 均领先 PaddleOCR-VL-1.5,同时依然保持 0.9B 超紧凑 VLM 参数量和高效率。
关键指标:¶
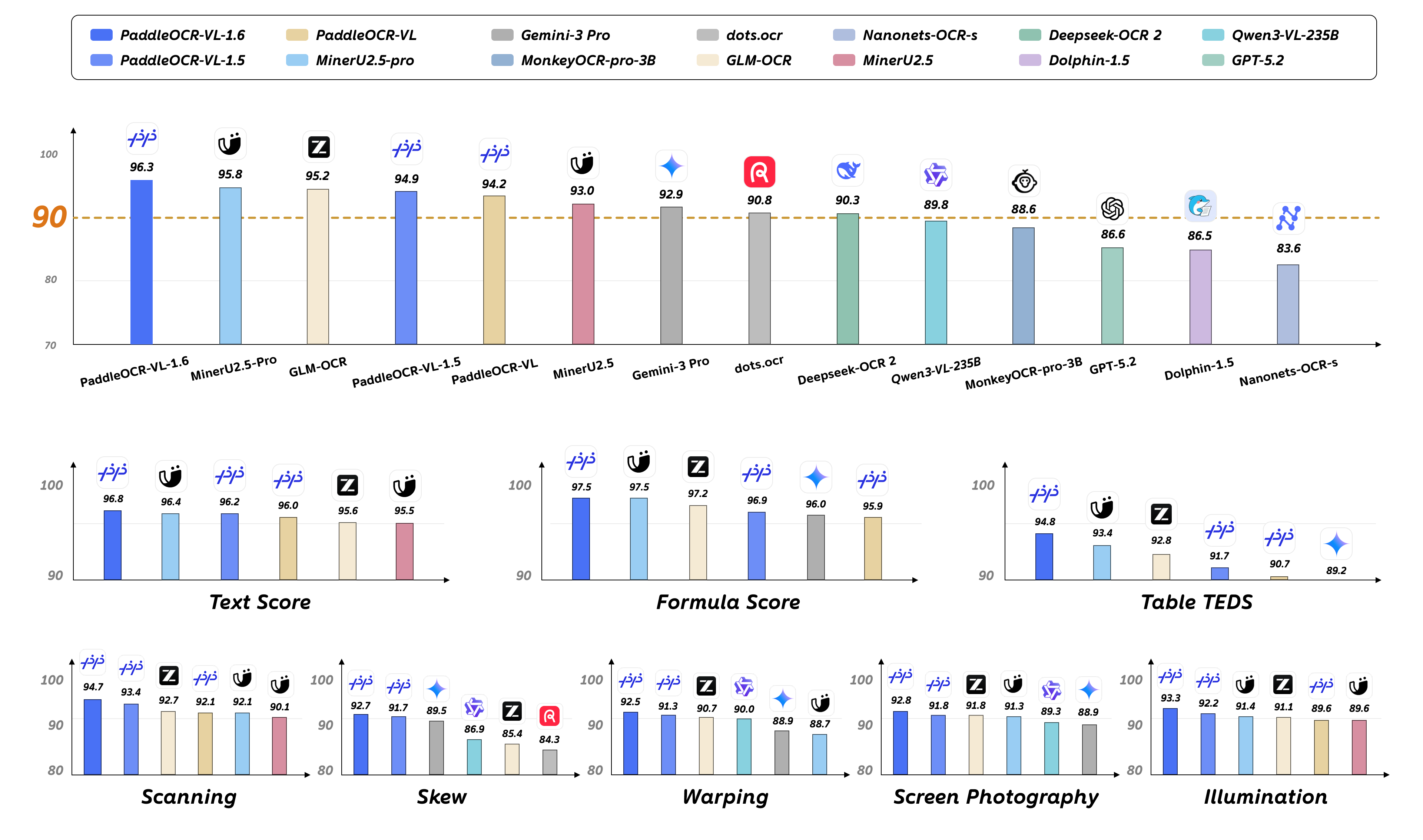
核心特性:¶
-
文档解析的SOTA性能: 凭借 0.9B 的参数量,PaddleOCR-VL-1.6 在 OmniDocBench v1.6 上达到了 96.33% 的准确率,超越了之前的 SOTA 模型 PaddleOCR-VL-1.5。在表格、公式和文本识别方面观察到了显著提升。
-
现实5大场景文档解析的SOTA性能: 具备更强的鲁棒性和真实场景的实用性。在扫描、弯曲、倾斜、屏摄和光照变化这五个真实扰动场景的评估中,表现优于主流的开源和闭源模型。
-
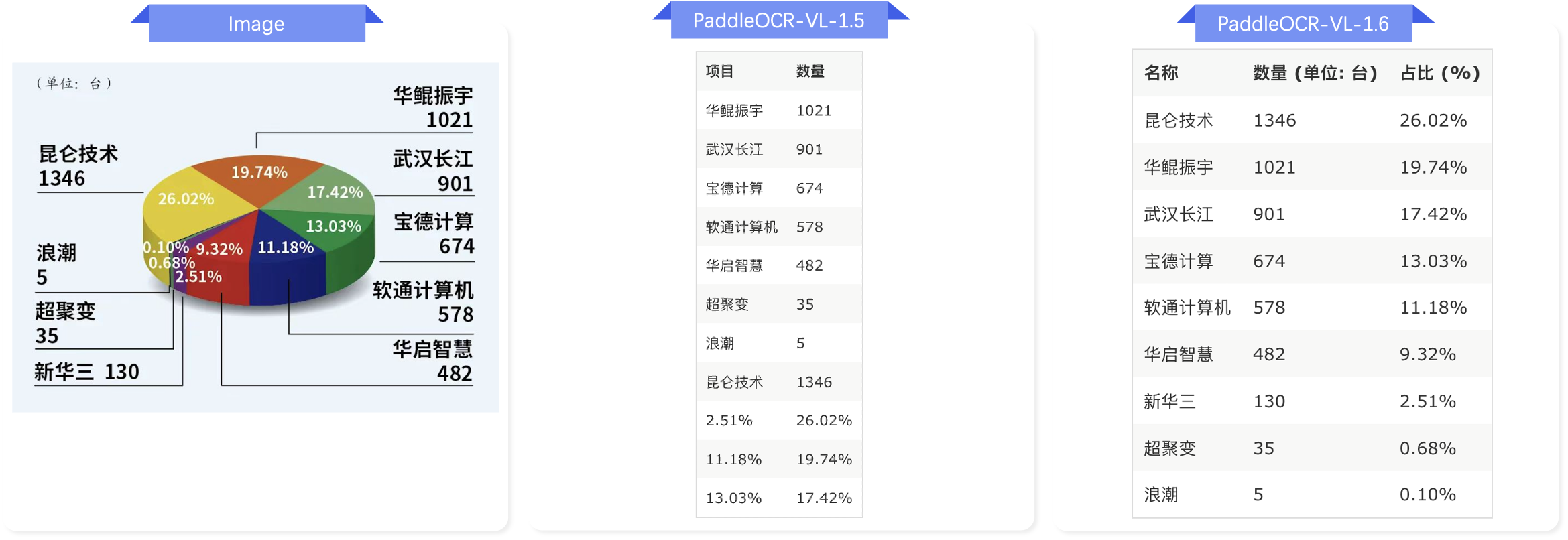
强化多元素识别能力: 除了版面解析能力的提升外,PaddleOCR-VL-1.6 进一步大幅度增强了对复杂表格,古籍 和 生僻字的识别能力,同时在 图表解析,印章识别,文字检测识别这三个原有能力上进一步提升。
-
0.9B紧凑架构: 沿用 PaddleOCR-VL系列的 0.9B 紧凑构架,零成本适配,即换即用。
二、技术架构¶
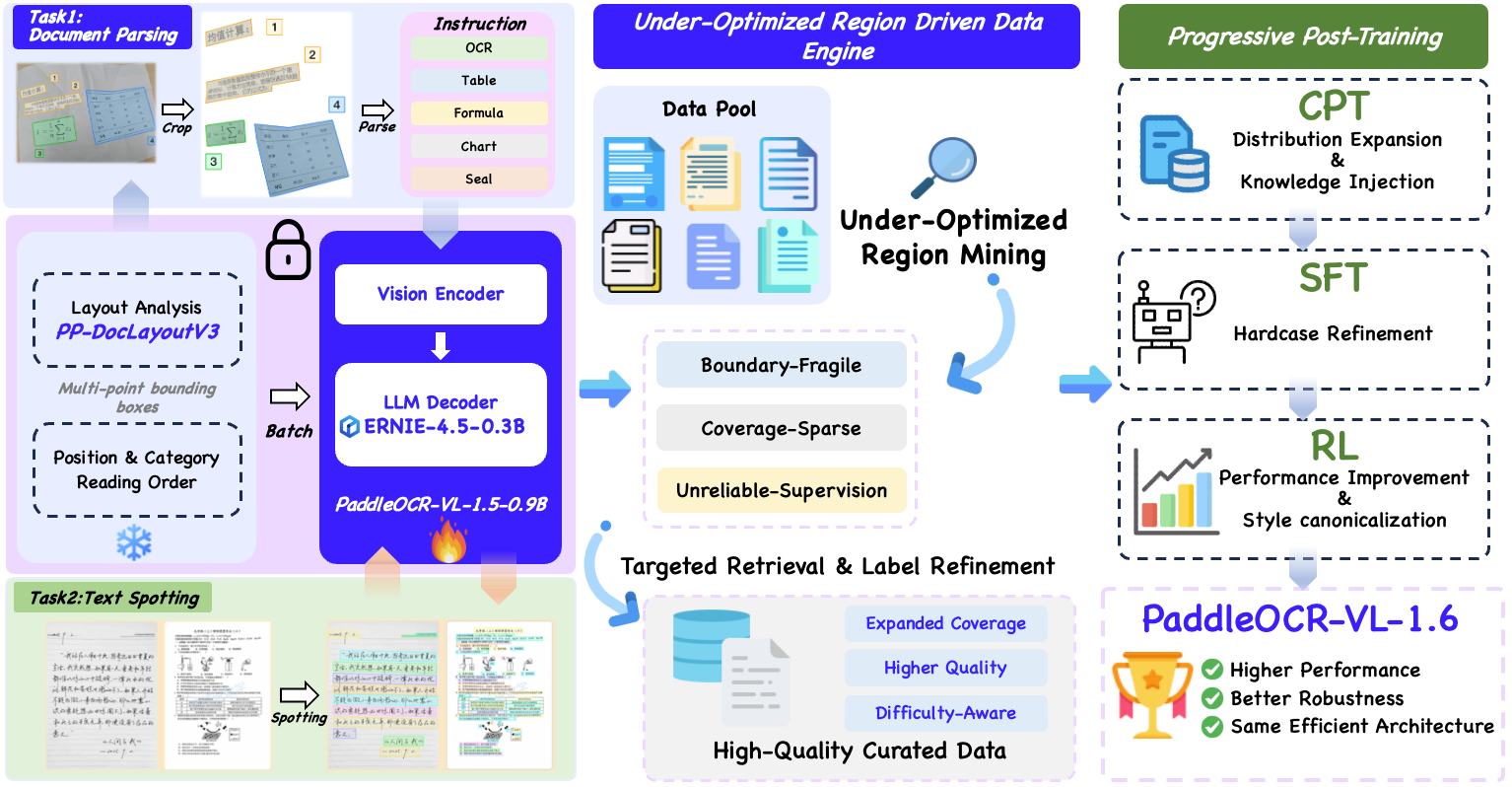
- 数据引擎: 以 PaddleOCR-VL-1.5 为出发点,系统性定位 PaddleOCR-VL-1.5 的欠优化区域,并设计高质量标签获取策略,针对性的进行数据优化。
- 渐进式后训练策略 从质量,难度,提升价值三个角度精细化划分数据,加载 PaddleOCR-VL-1.5 训练权重,结合不同的数据质量进行 继续预训练,监督微调,强化学习 三阶段的后训练策略,稳步提升模型性能。
三、 模型性能¶
1. OmniDocBench v1.6¶
PaddleOCR-VL-1.6 在 OmniDocBench v1.6 上的整体指标、文本、公式、表格均达到最先进的性能,其中在在阅读顺序方面,PaddleOCR-VL-1.6也取得了较为领先的指标。¶
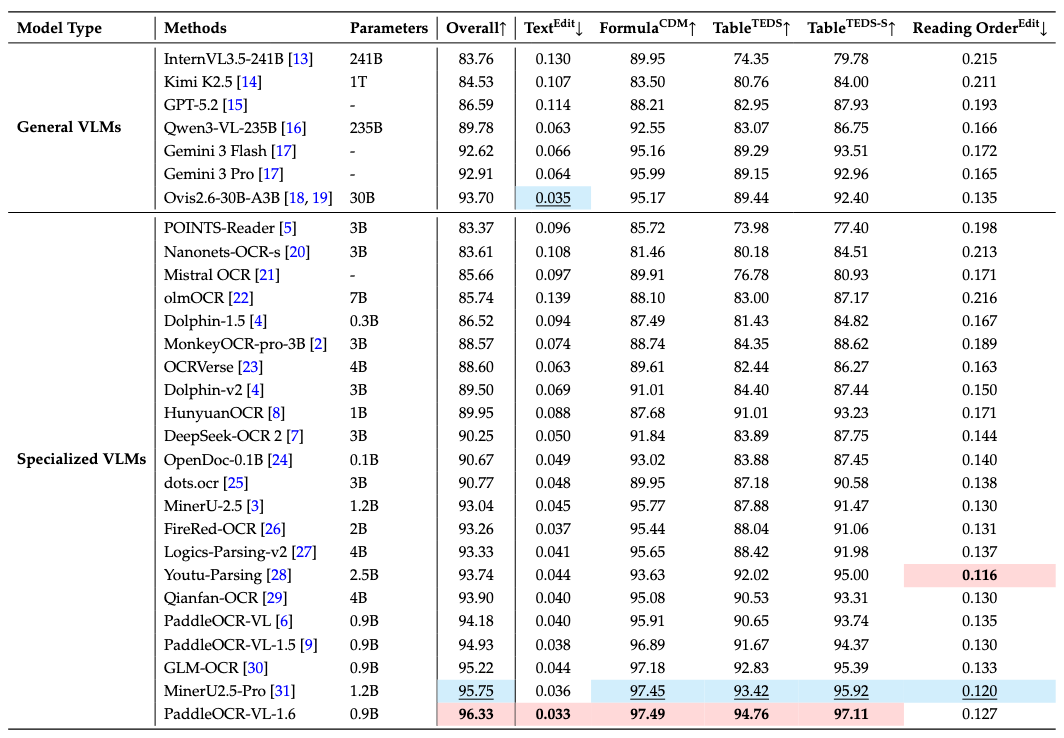
注: - 性能指标引自 OmniDocBench 官方排行榜。
2. Real5-OmniDocBench¶
在扫描、扭曲、屏摄、光照和倾斜这五个多样化且具挑战性的场景中,PaddleOCR-VL-1.6 均创下了新的 SOTA 记录。¶
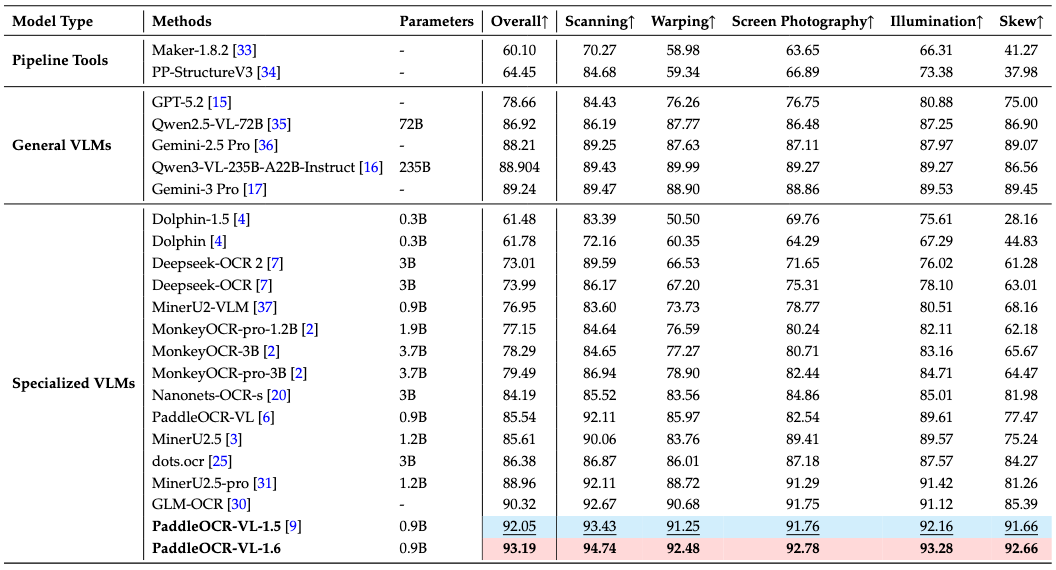
注: - Real5-OmniDocBench 是 PaddleOCR团队 基于 OmniDocBench v1.5 数据集构建的、面向真实场景的全新基准测试。该数据集包含五个不同场景:扫描 (Scanning)、扭曲 (Warping)、屏摄 (Screen-photography)、光照 (Illumination) 和倾斜 (Skew)。更多详情请参阅 Real5-OmniDocBench.
四、推理部署性能¶
PaddleOCR-VL-1.6 和 PaddleOCR-VL-1.5 采用完全相同的模型架构设计,因此有完全相同的推理速度。关于PaddleOCR-VL-1.5推理速度的说明可以参考 PaddleOCR-VL-1.5推理速度 。
5. 可视化¶
和 PaddleOCR-VL-1.5 的对比¶
古籍识别¶



图表解析¶

公式识别¶



生僻字识别¶


印章识别¶


表格识别¶


