PaddleOCR-VL-1.6 Introduction
1. Introduction to PaddleOCR-VL-1.6¶
PaddleOCR-VL-1.6 further optimizes PaddleOCR-VL-1.5 by systematically analyzing under-optimized areas in the current model, applying targeted data optimization, and adopting refined post-training strategies. It achieves a new state-of-the-art (SOTA) result of 96.33% on the OmniDocBench v1.6 document parsing benchmark. PaddleOCR-VL-1.6 also reaches SOTA performance across all scenarios on Real5-OmniDocBench, a benchmark designed to evaluate robustness against real-world physical distortions. In addition, PaddleOCR-VL-1.6 outperforms PaddleOCR-VL-1.5 on three subtasks: seal recognition, text detection and recognition, and chart recognition, while still maintaining an ultra-compact 0.9B-parameter VLM and high efficiency.
Key Metrics:¶
Core Features:¶
-
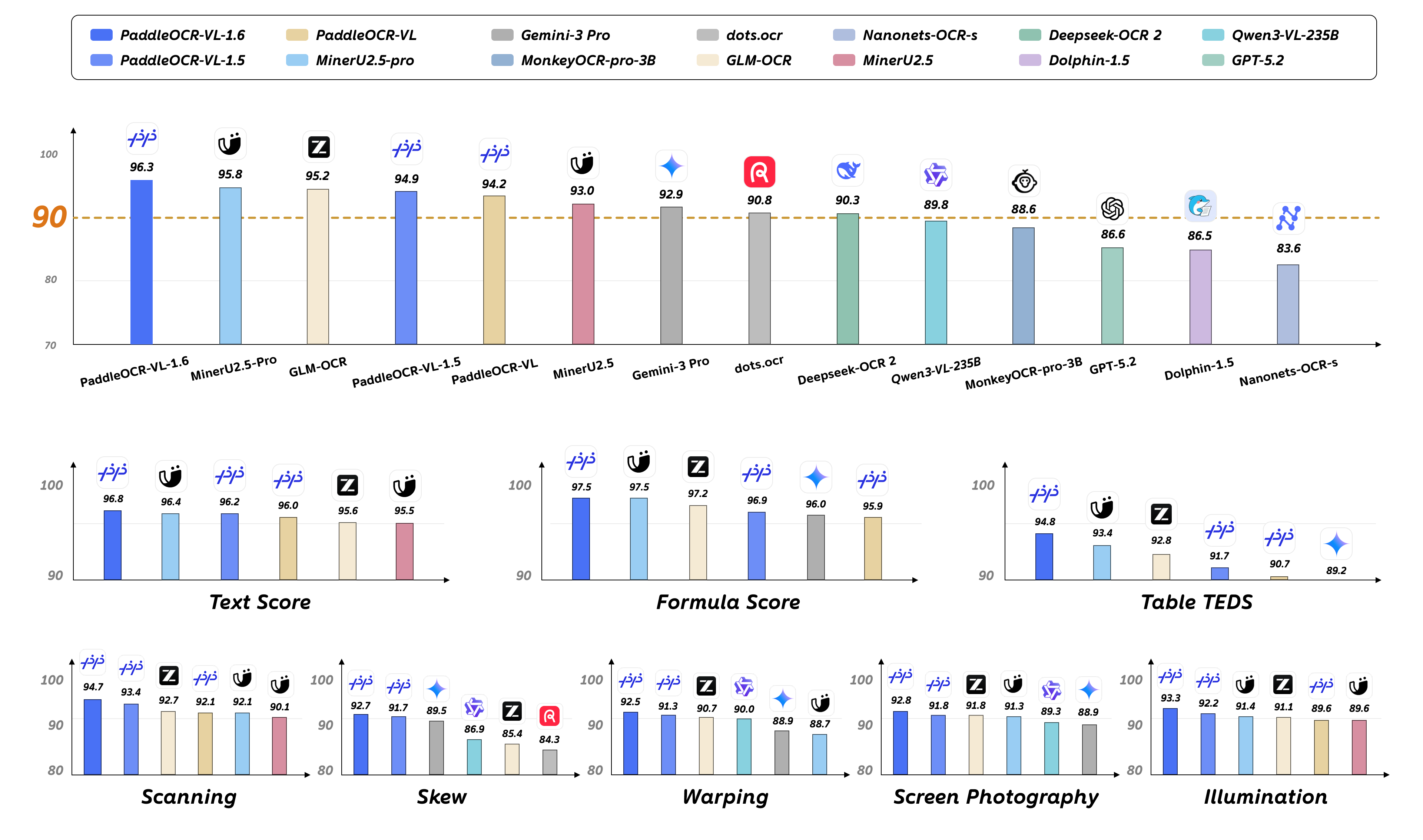
SOTA performance in document parsing: With only 0.9B parameters, PaddleOCR-VL-1.6 achieves 96.33% accuracy on OmniDocBench v1.6, surpassing the previous SOTA model, PaddleOCR-VL-1.5. Significant improvements are observed in table, formula, and text recognition.
-
SOTA performance for document parsing across five real-world scenarios: PaddleOCR-VL-1.6 offers stronger robustness and practicality in real-world use cases. In evaluations across five real-world distortion scenarios—scanning, warping, skew, screen photography, and illumination variation—it outperforms mainstream open-source and closed-source models.
-
Enhanced multi-element recognition capabilities: Beyond improved layout parsing, PaddleOCR-VL-1.6 substantially strengthens recognition of complex tables, ancient books, and rare Chinese characters, while further improving three existing capabilities: chart parsing, seal recognition, and text detection and recognition.
-
Compact 0.9B architecture: PaddleOCR-VL-1.6 follows the compact 0.9B architecture of the PaddleOCR-VL series, enabling zero-cost adaptation and drop-in replacement.
2. Technical Architecture¶
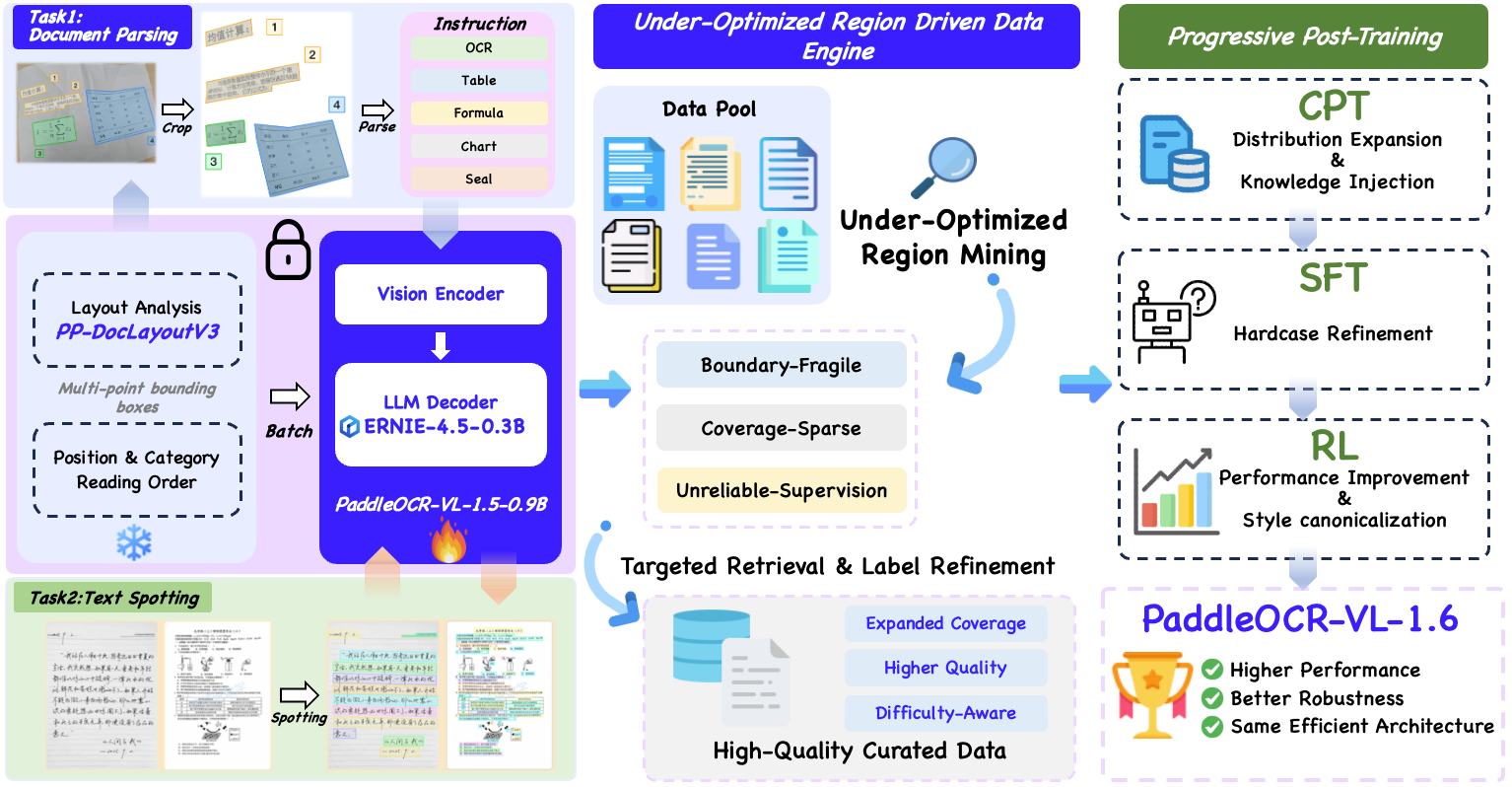
- Data engine: Starting from PaddleOCR-VL-1.5, the data engine systematically identifies under-optimized areas in PaddleOCR-VL-1.5, designs strategies for obtaining high-quality labels, and performs targeted data optimization.
- Progressive post-training strategy: Data is carefully categorized from three perspectives: quality, difficulty, and improvement value. The training weights of PaddleOCR-VL-1.5 are loaded, and a three-stage post-training strategy—continued pre-training, supervised fine-tuning, and reinforcement learning—is applied according to different data quality levels to steadily improve model performance.
3. Model Performance¶
1. OmniDocBench v1.6¶
PaddleOCR-VL-1.6 achieves state-of-the-art performance on OmniDocBench v1.6 in overall metrics, text, formulas, and tables. It also delivers leading results in reading order.¶
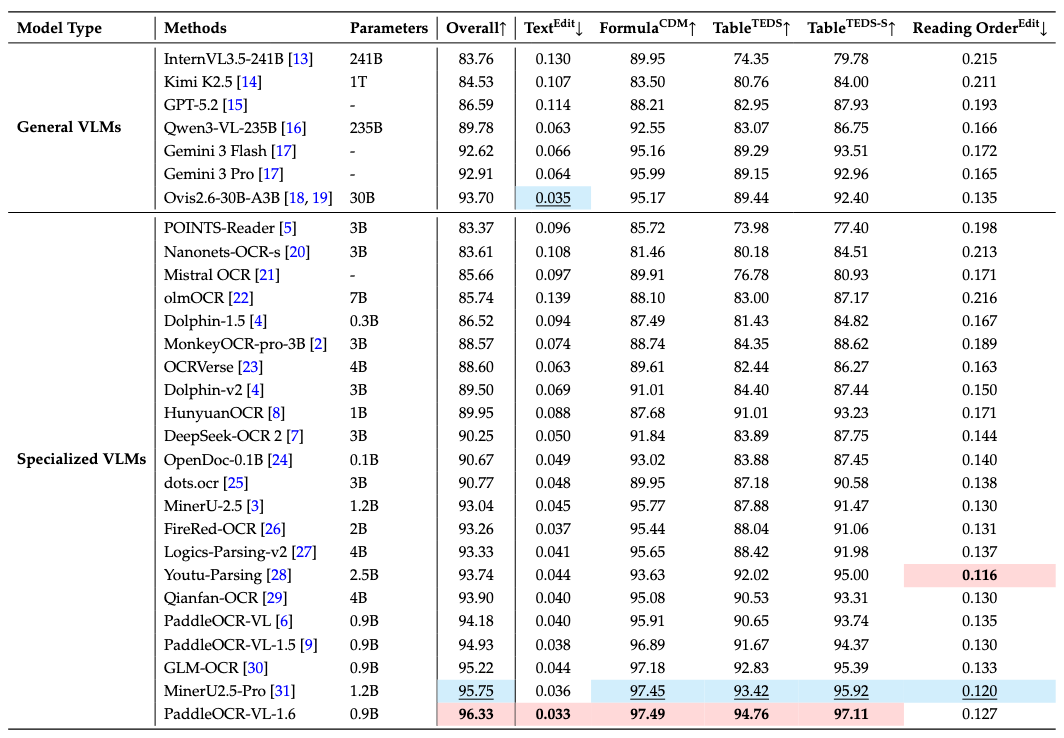
Note: - Performance metrics are cited from the official OmniDocBench leaderboard.
2. Real5-OmniDocBench¶
PaddleOCR-VL-1.6 sets new SOTA records across five diverse and challenging scenarios: scanning, warping, screen photography, illumination, and skew.¶
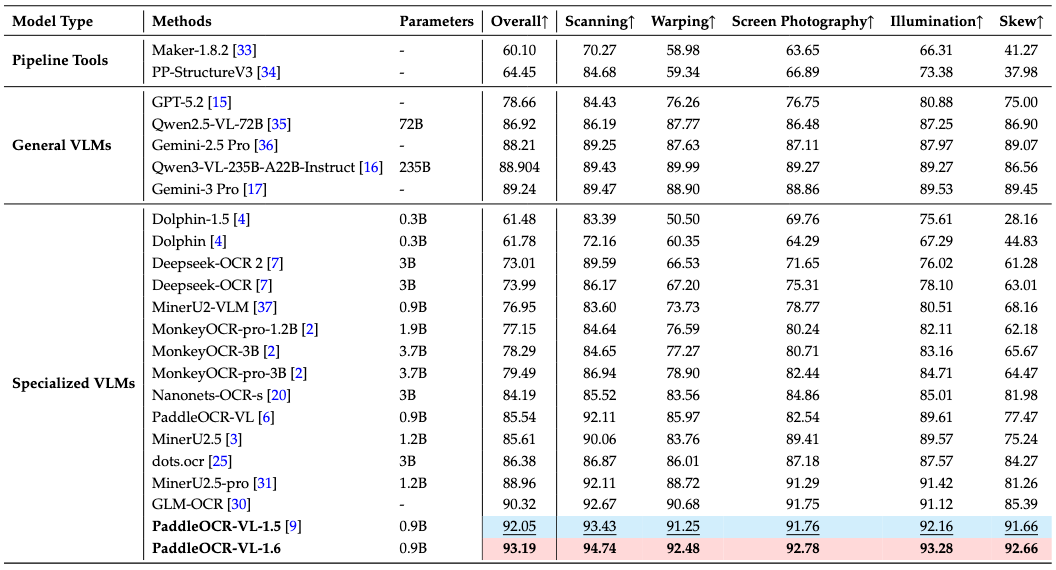
Note: - Real5-OmniDocBench is a new real-world benchmark built by the PaddleOCR team based on the OmniDocBench v1.5 dataset. It contains five scenarios: Scanning, Warping, Screen-photography, Illumination, and Skew. For more details, see Real5-OmniDocBench.
4. Inference and Deployment Performance¶
PaddleOCR-VL-1.6 and PaddleOCR-VL-1.5 use exactly the same model architecture design, so they have identical inference speeds. For details about the inference speed of PaddleOCR-VL-1.5, refer to PaddleOCR-VL-1.5 inference speed.
5. Visualization¶
Comparison with PaddleOCR-VL-1.5¶
Ancient Book Recognition¶



Chart Parsing¶

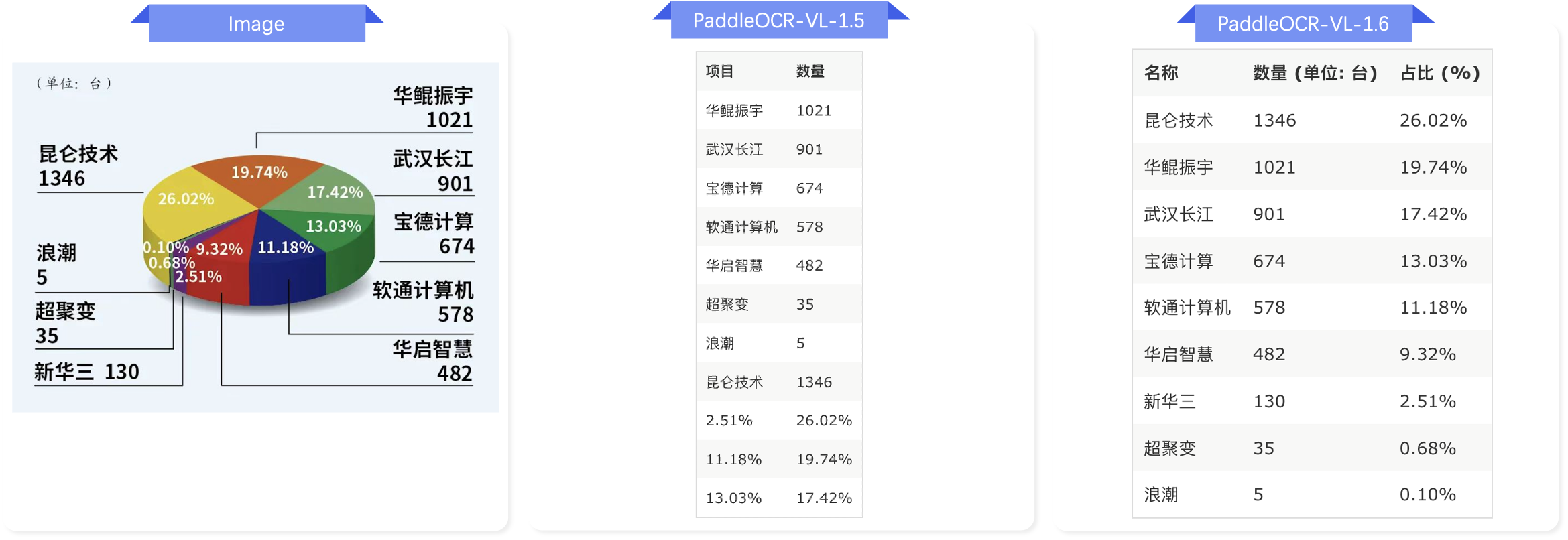
Formula Recognition¶



Rare Chinese Character Recognition¶


Seal Recognition¶


Table Recognition¶


