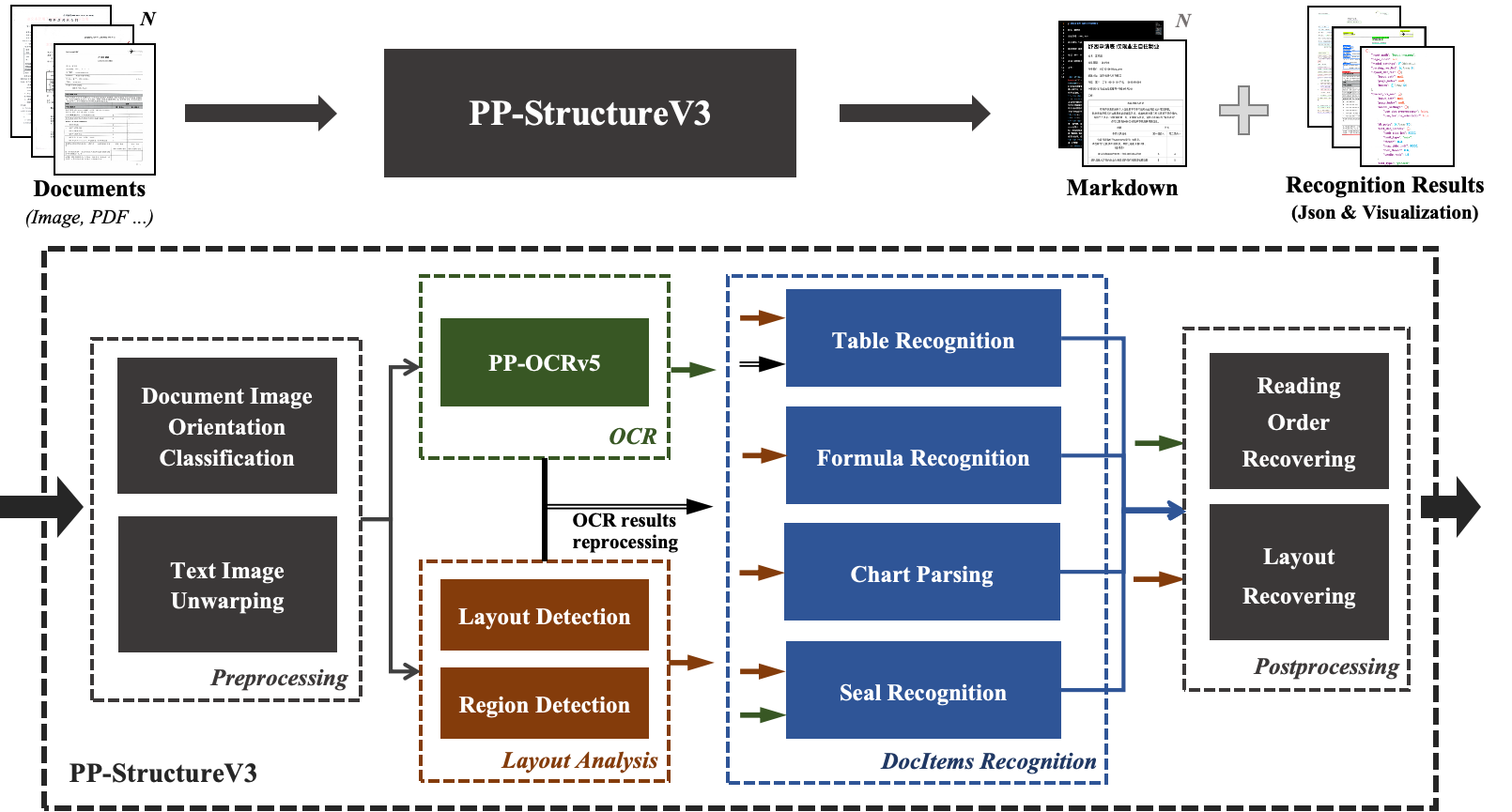
Introduction to PP-StructureV3¶
PP-StructureV3 pipeline, based on the Layout Parsing v1 pipeline, has strengthened the ability of layout detection, table recognition, and formula recognition. It has also added the ability to understand charts and restore reading order, as well as the ability to convert results into Markdown files. In various document data, it performs excellently and can handle more complex document data. This pipeline also provides flexible service-oriented deployment methods, supporting the use of multiple programming languages on various hardware. Moreover, it also provides the ability for secondary development. You can train and optimize on your own dataset based on this pipeline, and the trained model can be seamlessly integrated.
Key Metrics¶
| Method Type | Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableEdit↓ | Read OrderEdit↓ | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools | PP-structureV3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | 0.159 | 0.109 | 0.069 | 0.091 |
| MinerU-0.9.3 | 0.15 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 0.18 | 0.344 | 0.079 | 0.292 | |
| MinerU-1.3.11 | 0.166 | 0.310 | 0.0826 | 0.2000 | 0.3368 | 0.6236 | 0.1613 | 0.1833 | 0.0834 | 0.2316 | |
| Marker-1.2.3 | 0.336 | 0.556 | 0.08 | 0.315 | 0.53 | 0.883 | 0.619 | 0.685 | 0.114 | 0.34 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 0.243 | 0.32 | 0.108 | 0.304 | |
| Docling-2.14.0 | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | 0.627 | 0.81 | 0.313 | 0.837 | |
| Pix2Text-1.1.2.3 | 0.32 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured-0.17.2 | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse-0.7.0 | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.284 | 0.639 | 0.595 | 0.641 | |
| Expert VLMs | GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.36 | 0.528 | 0.459 | 0.52 | 0.141 | 0.28 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 0.572 | 1 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 0.6 | 0.65 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M_transformer | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 0.729 | 0.907 | 0.227 | 0.522 | |
| General VLMs | Gemini2.0-flash | 0.191 | 0.264 | 0.091 | 0.139 | 0.389 | 0.584 | 0.193 | 0.206 | 0.092 | 0.128 |
| Gemini2.5-Pro | 0.148 | 0.212 | 0.055 | 0.168 | 0.356 | 0.439 | 0.13 | 0.119 | 0.049 | 0.121 | |
| GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 0.234 | 0.329 | 0.128 | 0.251 | |
| Qwen2-VL-72B | 0.252 | 0.327 | 0.096 | 0.218 | 0.404 | 0.487 | 0.387 | 0.408 | 0.119 | 0.193 | |
| Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 0.341 | 0.262 | 0.106 | 0.168 | |
| InternVL2-76B | 0.44 | 0.443 | 0.353 | 0.29 | 0.543 | 0.701 | 0.547 | 0.555 | 0.317 | 0.228 | |
The above data is from: * OmniDocBench * OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
End to End Benchmark¶
The performance of PP-StructureV3 and MinerU with different configurations under different GPU environments are as follows.
Requirements: * Paddle 3.0 * PaddleOCR 3.0.0 * MinerU 1.3.10 * CUDA 11.8 * cuDNN 8.9
Local inference¶
Local inference was tested with both V100 and A100 GPU, evaluating the performance of PP-StructureV3 under 6 different configurations. The test data consists of 15 PDF files, totaling 925 pages, including elements such as tables, formulas, seals, and charts.
In the following PP-StructureV3 configuration, please refer to PP-OCRv5 for OCR model details, see Formula Recognition for formula recognition model details, and refer to Text Detection for the max_side_limit setting of the text detection module.
Env: NVIDIA Tesla V100 + Intel Xeon Gold 6271C¶
| Methods | Configurations | Average time per page (s) | Average CPU (%) | Peak RAM Usage (GB) | Average RAM Usage (GB) | Average GPU (%) | Peak VRAM Usage (GB) | Average VRAM Usage (GB) | |||
| PP-StructureV3 | OCR Models | Formula Recognition Model | Chart Recognition Model | text detection module max_side_limit | |||||||
| Server | PP-FormulaNet-L | ✗ | 4096 | 1.77 | 111.4 | 6.7 | 5.2 | 38.9 | 17.0 | 16.5 | |
| Server | PP-FormulaNet-L | ✔ | 4096 | 4.09 | 105.3 | 5.5 | 4.0 | 24.7 | 17.0 | 16.6 | |
| Mobile | PP-FormulaNet-L | ✗ | 4096 | 1.56 | 113.7 | 6.6 | 4.9 | 29.1 | 10.7 | 10.6 | |
| Server | PP-FormulaNet-M | ✗ | 4096 | 1.42 | 112.9 | 6.8 | 5.1 | 38 | 16.0 | 15.5 | |
| Mobile | PP-FormulaNet-M | ✗ | 4096 | 1.15 | 114.8 | 6.5 | 5.0 | 26.1 | 8.4 | 8.3 | |
| Mobile | PP-FormulaNet-M | ✗ | 1200 | 0.99 | 113 | 7.0 | 5.6 | 29.2 | 8.6 | 8.5 | |
| MinerU | - | 1.57 | 142.9 | 13.3 | 11.8 | 43.3 | 31.6 | 9.7 | |||
NVIDIA A100 + Intel Xeon Platinum 8350C¶
| Methods | Configurations | Average time per page (s) | Average CPU (%) | Peak RAM Usage (GB) | Average RAM Usage (GB) | Average GPU (%) | Peak VRAM Usage (GB) | Average VRAM Usage (GB) | |||
| PP-StructureV3 | OCR Models | Formula Recognition Model | Chart Recognition Model | text detection module max_side_limit | |||||||
| Server | PP-FormulaNet-L | ✗ | 4096 | 1.12 | 109.8 | 9.2 | 7.8 | 29.8 | 21.8 | 21.1 | |
| Server | PP-FormulaNet-L | ✔ | 4096 | 2.76 | 103.7 | 9.0 | 7.7 | 24 | 21.8 | 21.1 | |
| Mobile | PP-FormulaNet-L | ✗ | 4096 | 1.04 | 110.7 | 9.3 | 7.8 | 22 | 12.2 | 12.1 | |
| Server | PP-FormulaNet-M | ✗ | 4096 | 0.95 | 111.4 | 9.1 | 7.8 | 28.1 | 21.8 | 21.0 | |
| Mobile | PP-FormulaNet-M | ✗ | 4096 | 0.89 | 112.1 | 9.2 | 7.8 | 18.5 | 11.4 | 11.2 | |
| Mobile | PP-FormulaNet-M | ✗ | 1200 | 0.64 | 113.5 | 10.2 | 8.5 | 23.7 | 11.4 | 11.2 | |
| MinerU | - | 1.06 | 168.3 | 18.3 | 16.8 | 27.5 | 76.9 | 14.8 | |||
Serving Inference¶
The serving inference test is based on the NVIDIA A100 + Intel Xeon Platinum 8350C environment, with test data consisting of 1500 images, including tables, formulas, seals, charts, and other elements.
| Instances Number | Concurrent Requests Number | Throughput | Average Latency (s) | Success Number/Total Number | 4 GPUs ✖️ 1 instance/gpu | 4 | 1.69 | 2.36 | 100% | 4 GPUs ✖️ 4 instances/gpu | 16 | 4.05 | 3.87 | 100% |
Pipeline benchmark data¶
Click to expand/collapse the table
| Pipeline configuration | Hardware | Avg. inference time (s) | Peak CPU utilization (%) | Avg. CPU utilization (%) | Peak host memory (MB) | Avg. host memory (MB) | Peak GPU utilization (%) | Avg. GPU utilization (%) | Peak device memory (MB) | Avg. device memory (MB) |
|---|---|---|---|---|---|---|---|---|---|---|
| PP_StructureV3-default | Intel 8350C + A100 | 1.38 | 1384.60 | 113.26 | 5781.59 | 3431.21 | 100 | 32.79 | 37370.00 | 34165.68 |
| Intel 6271C + V100 | 2.38 | 608.70 | 109.96 | 6388.91 | 3737.19 | 100 | 39.08 | 26824.00 | 24581.61 | |
| Intel 8563C + H20 | 1.36 | 744.30 | 112.82 | 6199.01 | 3865.78 | 100 | 43.81 | 35132.00 | 32077.12 | |
| Intel 8350C + A10 | 1.74 | 418.50 | 105.96 | 6138.25 | 3503.41 | 100 | 48.54 | 18536.00 | 18353.93 | |
| Intel 6271C + T4 | 3.70 | 434.40 | 105.45 | 6865.87 | 3595.68 | 100 | 71.92 | 13970.00 | 12668.58 | |
| PP_StructureV3-pp | Intel 8350C + A100 | 3.50 | 679.30 | 105.96 | 13850.20 | 5146.50 | 100 | 14.01 | 37656.00 | 34716.95 |
| Intel 6271C + V100 | 5.03 | 494.20 | 105.63 | 13542.94 | 4833.55 | 100 | 20.36 | 29402.00 | 26607.92 | |
| Intel 8563C + H20 | 3.17 | 481.50 | 105.13 | 14179.97 | 5608.80 | 100 | 19.35 | 35454.00 | 32512.19 | |
| PP_StructureV3-full | Intel 8350C + A100 | 8.92 | 697.30 | 102.88 | 13777.07 | 4573.65 | 100 | 18.39 | 38776.00 | 37554.09 |
| Intel 6271C + V100 | 13.12 | 437.40 | 102.36 | 13974.00 | 4484.00 | 100 | 17.50 | 29878.00 | 28733.59 | |
| PP_StructureV3-seal | Intel 8350C + A100 | 1.39 | 747.50 | 112.55 | 5788.79 | 3742.03 | 100 | 33.81 | 38966.00 | 35832.44 |
| Intel 6271C + V100 | 2.44 | 630.10 | 110.18 | 6343.39 | 3725.98 | 100 | 42.23 | 28078.00 | 25834.70 | |
| Intel 8563C + H20 | 1.40 | 792.20 | 113.63 | 6673.60 | 4417.34 | 100 | 46.33 | 35530.00 | 32516.87 | |
| Intel 8350C + A10 | 1.75 | 422.40 | 106.08 | 6068.87 | 3973.49 | 100 | 50.12 | 19630.00 | 18374.37 | |
| Intel 6271C + T4 | 3.76 | 400.30 | 105.10 | 6296.28 | 3651.42 | 100 | 72.57 | 14304.00 | 13268.36 | |
| PP_StructureV3-chart | Intel 8350C + A100 | 7.70 | 746.80 | 102.69 | 6355.58 | 4006.48 | 100 | 22.38 | 37380.00 | 36730.73 |
| Intel 6271C + V100 | 10.58 | 599.20 | 102.51 | 5754.14 | 3333.78 | 100 | 21.99 | 26820.00 | 26253.70 | |
| Intel 8350C + A10 | 8.03 | 413.30 | 101.31 | 6473.29 | 3689.84 | 100 | 26.19 | 18540.00 | 18494.69 | |
| Intel 6271C + T4 | 11.69 | 460.90 | 101.85 | 6503.12 | 3524.06 | 100 | 46.81 | 13966.00 | 12481.94 | |
| PP_StructureV3-notable | Intel 8350C + A100 | 1.24 | 738.30 | 110.45 | 5638.16 | 3278.30 | 100 | 35.32 | 30320.00 | 27026.17 |
| Intel 6271C + V100 | 2.24 | 452.40 | 107.79 | 5579.15 | 3635.95 | 100 | 43.00 | 23098.00 | 20684.43 | |
| Intel 8563C + H20 | 1.18 | 989.00 | 107.71 | 6041.76 | 4024.76 | 100 | 50.67 | 33780.00 | 29733.15 | |
| Intel 8350C + A10 | 1.58 | 225.00 | 102.56 | 5518.10 | 3333.08 | 100 | 49.90 | 21532.00 | 18567.99 | |
| Intel 6271C + T4 | 3.40 | 413.30 | 103.58 | 5874.88 | 3662.49 | 100 | 76.82 | 13764.00 | 11890.62 | |
| PP_StructureV3-noformula | Intel 6271C | 7.85 | 1172.50 | 964.70 | 17739.00 | 11101.02 | N/A | N/A | N/A | N/A |
| Intel 8350C | 8.83 | 1053.50 | 970.64 | 15463.48 | 9408.19 | N/A | N/A | N/A | N/A | |
| Intel 8350C + A100 | 0.84 | 788.60 | 124.25 | 6246.39 | 3674.32 | 100 | 30.57 | 40084.00 | 37358.45 | |
| Intel 6271C + V100 | 1.42 | 606.20 | 115.53 | 7015.57 | 3707.03 | 100 | 35.63 | 29540.00 | 27620.28 | |
| Intel 8563C + H20 | 0.87 | 644.10 | 119.23 | 6895.76 | 4222.85 | 100 | 50.00 | 36878.00 | 34104.59 | |
| Intel 8350C + A10 | 1.03 | 377.50 | 106.87 | 5819.88 | 3830.19 | 100 | 42.87 | 19340.00 | 17550.94 | |
| Intel 6271C + T4 | 2.02 | 430.20 | 109.21 | 6600.62 | 3824.18 | 100 | 65.75 | 14332.00 | 12712.18 | |
| PP_StructureV3-lightweight | Intel 6271C | 4.36 | 1189.70 | 995.78 | 14000.50 | 9374.97 | N/A | N/A | N/A | N/A |
| Intel 8350C | 3.74 | 1049.60 | 967.77 | 12960.96 | 7644.25 | N/A | N/A | N/A | N/A | |
| Hygon 7490 + P800 | 0.86 | 572.20 | 120.84 | 8290.49 | 3569.44 | N/A | N/A | N/A | N/A | |
| Intel 8350C + A100 | 0.61 | 823.40 | 126.25 | 9258.22 | 3776.63 | 52 | 18.95 | 7456.00 | 7131.95 | |
| Intel 6271C + V100 | 1.07 | 686.80 | 116.70 | 9381.75 | 4126.28 | 58 | 22.92 | 8450.00 | 8083.30 | |
| Intel 8563C + H20 | 0.46 | 999.00 | 122.21 | 9734.78 | 4516.40 | 61 | 24.41 | 7524.00 | 7167.52 | |
| Intel 8350C + A10 | 0.70 | 355.40 | 111.51 | 9415.45 | 4094.06 | 89 | 30.85 | 7248.00 | 6927.58 | |
| M4 | 12.22 | 223.60 | 107.35 | 9531.22 | 7884.61 | N/A | N/A | N/A | N/A | |
| Intel 6271C + T4 | 1.13 | 461.40 | 112.16 | 7923.09 | 3837.31 | 85 | 41.67 | 8218.00 | 7902.04 |
| Pipeline configuration | description |
|---|---|
| PP_StructureV3-default | Default configuration |
| PP_StructureV3-pp | Based on the default configuration, document image preprocessing is enabled |
| PP_StructureV3-full | Based on the default configuration, document image preprocessing and chart parsing are enabled |
| PP_StructureV3-seal | Based on the default configuration, seal text recognition is enabled |
| PP_StructureV3-chart | Based on the default configuration, chart parsing is enabled |
| PP_StructureV3-notable | Based on the default configuration, table recognition is disabled |
| PP_StructureV3-noformula | Based on the default configuration, formula recognition is disabled |
| PP_StructureV3-lightweight | Based on the default configuration, all task models are replaced with lightweight versions |
- Test environment:
- PaddlePaddle 3.1.0、CUDA 11.8、cuDNN 8.9
- PaddleX @ develop (f1eb28e23cfa54ce3e9234d2e61fcb87c93cf407)
- Docker image: ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddle:3.1.0-gpu-cuda11.8-cudnn8.9
- Test data:
- Test data containing 280 images including tables, seals, formulas, and charts.
- Test strategy:
- Warm up with 20 samples, then repeat the full dataset once for performance testing.
- Note:
- Since we did not collect device memory data for NPU and XPU, the corresponding entries in the table are marked as N/A.
PP-StructureV3 Demo¶

FAQ¶
Q: What is the default model configuration? If I need higher accuracy, faster speed, or lower GPU memory usage, which parameters should I adjust or which models should I switch to? How significant is the impact on results?
A: By default, the largest models for each module are used. Section 3.3 demonstrates how different model selections affect GPU memory consumption and inference speed. You can choose an appropriate model based on your device capabilities and the complexity of your samples. Additionally, in the Python API or CLI, you can set the device parameter as <device_type>:<device_id1>,<device_id2>... (e.g., gpu:0,1,2,3) to enable multi-GPU parallel inference. If the built-in multi-GPU parallel inference does not meet your speed requirements, you may refer to the example code for multi-process parallel inference and further optimize it for your specific scenario: Multi-process Parallel Inference.
Q: Can PP-StructureV3 run on CPU?
A: While PP-StructureV3 is recommended to run on GPU for optimal performance, it also supports CPU inference. Thanks to a variety of configuration options and sufficient optimization for lightweight models, users can refer to section 3.3 to select lightweight configurations for CPU-only environments. For example, on an Intel 8350C CPU, the inference time per image is about 3.74 seconds.
Q: How can I integrate PP-StructureV3 into my own project?
A:
- For Python projects, you can directly integrate using the PaddleOCR Python API.
- For projects in other programming languages, it is recommended to use service-based deployment. PaddleOCR supports client-side integration in multiple languages, including C++, C#, Java, Go, and PHP. Please refer to the official documentation for details.
- If you need to interact with large language models, PaddleOCR also provides the MCP service. For more information, please refer to the MCP Server documentation.
Q: Can the serving handle concurrent requests?
A: In the basic service deployment solution, the service processes only one request at a time, which is mainly intended for quick validation, development pipeline integration, or scenarios that do not require concurrent processing. In the high-stability serving solution, the service also processes one request at a time by default, but users can achieve horizontal scaling and concurrent processing by adjusting the configuration as outlined in the service deployment guide.
Q: How can I reduce latency and increase throughput in serving?
A: PaddleOCR offers two types of service deployment solutions. Regardless of the solution used, enabling high-performance inference plugins can accelerate model inference and thus reduce latency. For the high-stability deployment solution, throughput can be further increased by adjusting the service configuration to run multiple instances, making full use of your hardware resources. Please refer to the documentation for more details on configuring high-stability serving.